车东西(公众号:chedongxi)
作者 | Janson
编辑 | 志豪
小米在国际计算机视觉顶会ECCV 2026上,一次性拿下了12篇论文!
车东西7月3日消息,据小米技术披露,在国际计算机视觉顶会ECCV 2026上,小米AI团队和小米自动驾驶团队多篇论文被录取。

▲小米12篇论文入选ECCV 2026
录用的这12篇论文中,有5篇都与自动驾驶直接相关,它们分别是CausalDrive、MindDrive、DriveVA、BeyondDrive和DriveFine。
五篇论文看似方向不同:有的研究世界模型,有的研究VLA决策,有的研究在线强化学习,有的研究安全负样本,有的研究轨迹自修正。
但放在一起看,它们其实都在回答同一个问题:自动驾驶如何从“看见道路”,走向“理解世界”?
毕竟,真实驾驶从来不只是识别车道线、车辆和行人。车需要理解前车刹车会带来什么连锁反应,旁车是否会让行,行人是否可能继续横穿。同时,系统也需要知道一个看似接近专家轨迹的动作,为什么可能在两秒后变成危险决策。
上述难题,也正是小米这五篇 ECCV 自动驾驶相关论文试图共同回答的问题。它们让模型不仅能感知环境,还能预测未来、理解交互、优化决策,并在风险出现前完成纠错。
值得一提的是,ECCV与CVPR、ICCV并称计算机视觉三大顶会,据小米技术披露,ECCV 2026共收到10473篇有效投稿,录取2883篇论文,录取率约27.5%,小米的12篇论文含金量可见一斑。
一、世界模型更新 不只要看见路还要“想象未来”
自动驾驶要真正走向复杂开放道路,不能只依赖当前帧里的车道线、车辆、行人和红绿灯。
真实驾驶更像是一场连续博弈:自车向左并线,旁车会不会减速?前车急刹,后车会如何反应?一个看似可行的轨迹,几秒后是否会把车辆带入冲突区域?
这就需要自动驾驶模型具备一种更高层的能力:世界模型。
所谓世界模型,简单来说,就是让模型在脑海中“预演未来”——不仅预测接下来画面会变成什么样,还要理解当前动作会怎样影响环境,周围交通参与者又会怎样反过来影响自车决策。
小米这次ECCV 2026自动驾驶相关论文中,CausalDrive和DriveVA正好代表了世界模型方向的两个关键问题。
1、CausalDrive:从“生成未来视频”到“模拟交通因果”
很多自动驾驶世界模型,过去更像是一个视频生成器,给它当前画面和一些条件,它生成未来几秒道路场景。
但问题是,真实交通不是一段被动播放的视频,而是一个会对自车动作作出反应的动态系统。
比如,自车准备并线,旁边车辆可能让行,也可能加速通过;前车突然刹车,后车会不会跟着减速,取决于距离、速度、驾驶意图等因素。
理解这些交通参与者之间的因果互动也是关键。
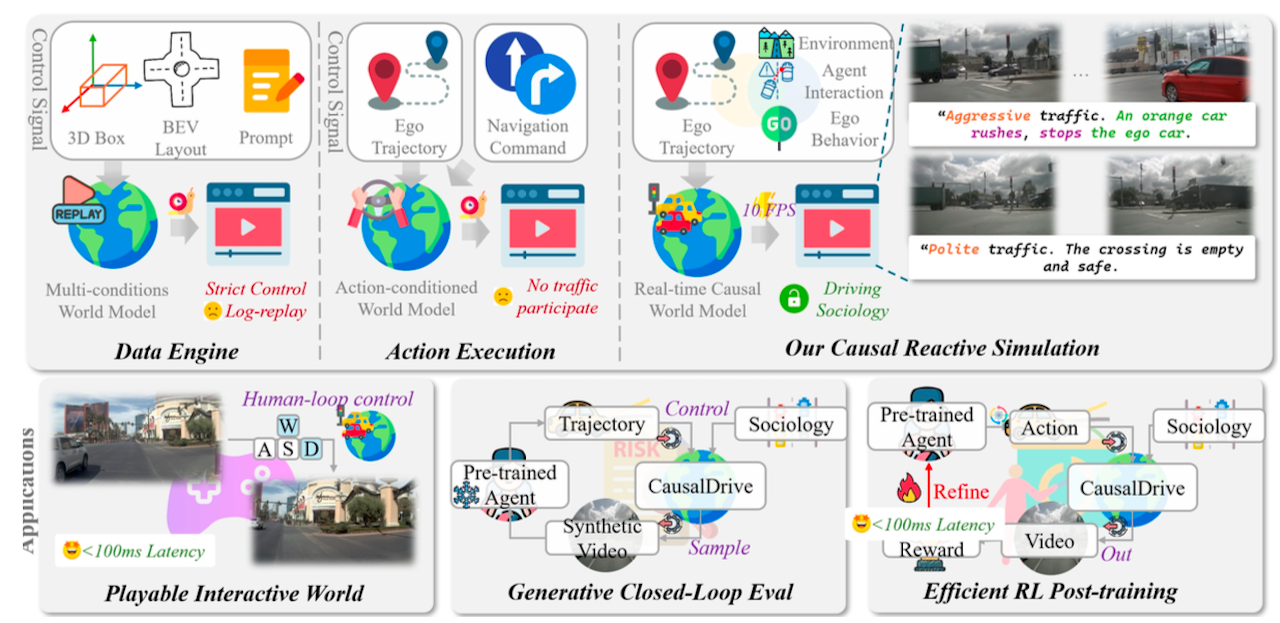
▲CausalDrive架构
CausalDrive的核心价值就在这里,论文指出,现有不少基于布局条件的驾驶世界模型依赖背景车辆未来轨迹,相当于提前知道了其他交通参与者未来会怎么走,因此并不是真正的交互式模拟。
而纯动作条件预测器又缺少对复杂交互的语义控制,并且推理延迟较高。
为了解决这个问题,CausalDrive只使用初始前视图像、自车轨迹和宏观文本提示,不输入未来NPC布局,从而迫使模型自己预测周围交通参与者的反应。
论文提出Context-Forced DMD(上下文强制DMD)架构,结合连续流匹配和自校正蒸馏,实现了12 FPS的交互式生成速度。
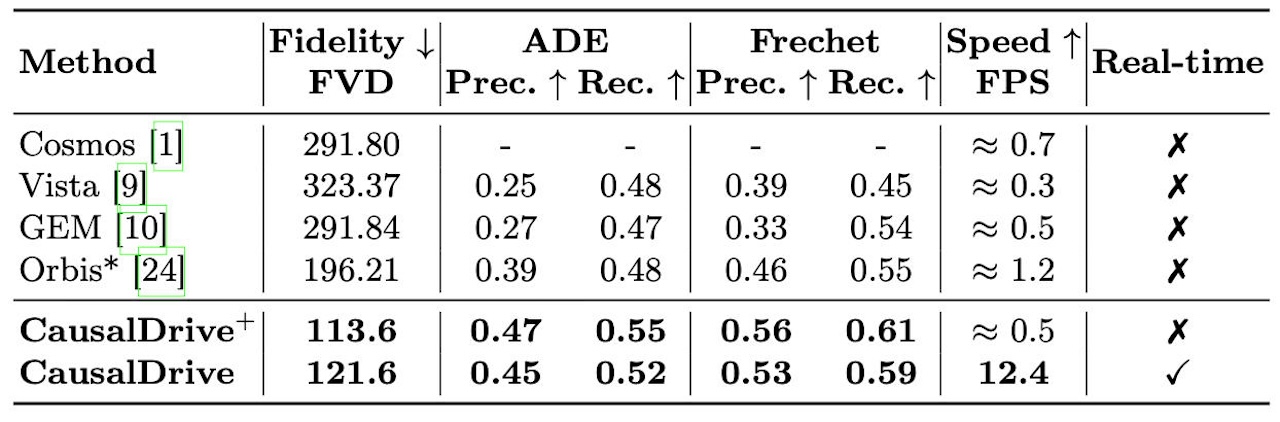
▲CausalDrive跑分
这意味着,CausalDrive把被动的视频生成器推进成一个可交互的神经仿真器,模型不仅要知道“未来画面长什么样”,还要理解“为什么会这样发生”。
这对自动驾驶的意义很直接。真实道路上的长尾情况很难全部靠采集数据覆盖,如果模型能构建可控、实时、可反事实推演的交通世界,就可以用来做闭环评测、强化学习训练,甚至人机交互式仿真。
论文也展示了其在生成式闭环评测、大规模强化学习后训练以及人在回路仿真中的应用潜力。
2、DriveVA:让“想象的未来”和“规划的轨迹”保持一致
如果说CausalDrive关注的是“交通世界如何因果互动”,那么DriveVA关注的是另一个关键问题:模型想象出来的未来,和它规划出来的轨迹,能不能一致?
现有不少世界模型规划方法,往往把未来视觉预测和轨迹规划分开处理,但这样做的问题是,模型可能“想象出一个未来”,却规划出一条并不匹配这个未来的路线。
也就是说,视频和动作是松耦合的。
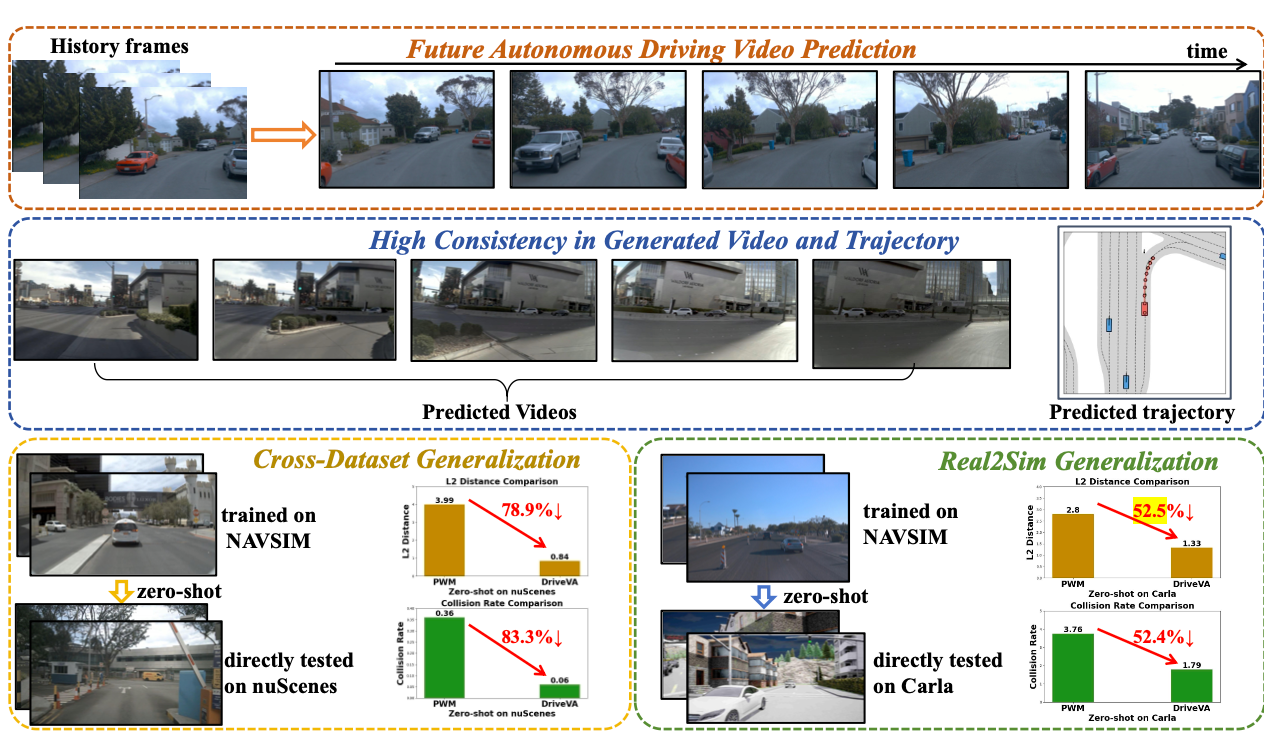
DriveVA的方法是,把未来视觉预测和车辆动作序列放进同一个shared latent generative process(共享潜在生成过程)中联合生成。
论文基于大规模预训练视频生成模型,继承其对时空动态、物理合理性和因果交互的建模先验,并使用DiT-based decoder(基于 DiT 的解码器)同时预测未来视频和车辆动作序列。
这个设计解决了自动驾驶中的一致性问题。对人类司机来说,驾驶决策通常不是割裂的:我们会一边观察周围车辆运动,一边预测几秒后的交通状态,同时调整自己的路径。
而DriveVA让自动驾驶模型也具备这种能力,让未来视觉和动作在同一套生成逻辑中完成。
▲DriveVA跑分
实验结果也比较有话题度,从跑分结果看,DriveVA在NAVSIM challenge上达到90.9 PDM score,并在零样本设置下展现出跨数据集、跨域泛化能力。
在nuScenes上,相比现有世界模型规划器,DriveVA将平均L2 error和collision rate分别降低78.9%和83.3%,在Bench2Drive/CARLA v2上则分别降低52.5%和52.4%。
二、VLA继续升级 生成轨迹并学会“为什么这样开”
如果说世界模型解决的是“未来会怎样变化”,那么自动驾驶还必须回答下一个问题:面对这个未来,车应该怎么做?
过去的端到端自动驾驶,更像是在学习专家轨迹,这种方式能覆盖大量常见场景,却很难解决两个问题:一是遇到训练数据之外的长尾情况,模型缺少主动试错和自我改进能力;二是轨迹一旦生成出错,后续很容易误差累积,难以及时回头修正。
这正是MindDrive和DriveFine两篇论文切入的地方,它们都属于VLA模型,让自动驾驶模型不只是“看图输出轨迹”,而是先理解场景、形成驾驶意图,再转化为具体行动。
1、MindDrive模型怎样在真实交互中学会更好的决策
自动驾驶当然可以通过强化学习“边试边学”,但难点在于,车辆动作是连续轨迹空间,速度、方向、加速度、位置点组合极其复杂,直接在轨迹里试错效率很低。
MindDrive的做法,是把试错从连续轨迹空间上移到语言决策空间。
模型先判断“减速让行”“保持车道”“缓慢左转避让行人”等驾驶意图,再由动作专家把这些意图映射成具体轨迹。
论文中,MindDrive采用共享视觉-语言模型基座,并通过两套LoRA(一种大模型参数高效微调技术)适配模块形成两个专家。
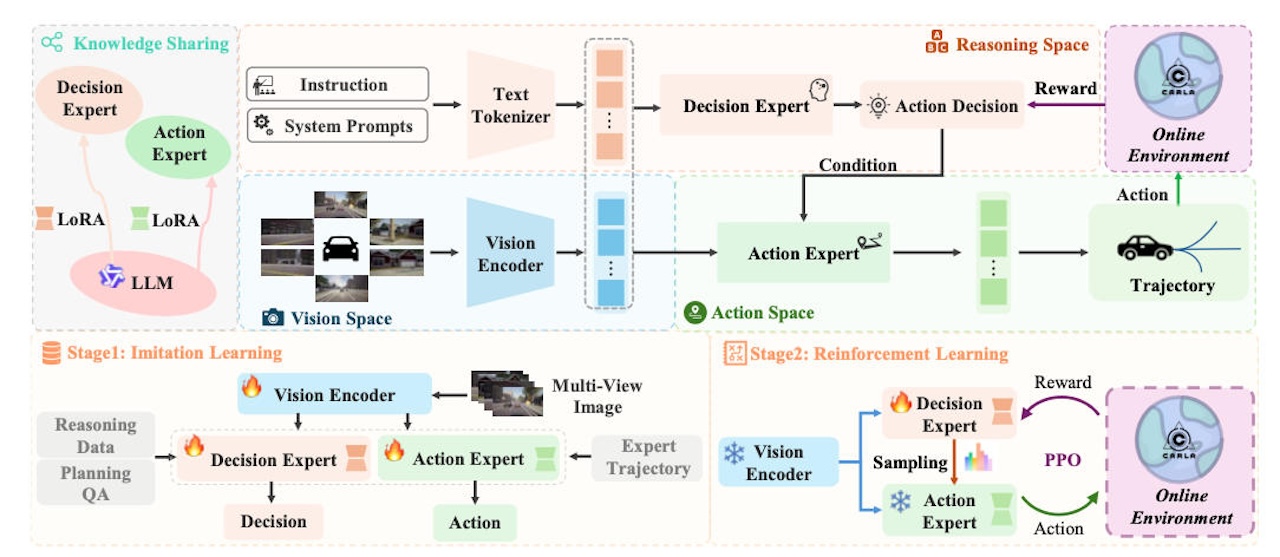
▲MindDrive架构
一个负责场景推理和驾驶决策,另一个负责把语言决策转成可执行轨迹;车辆执行后的轨迹奖励,则反馈到语言推理层,用来优化下一次决策。
这一步的意义在于,模型不再只是模仿“专家当时怎么开”,而是开始学习“这个场景下为什么应该这样开”。
强化学习也不再是在海量连续轨迹里盲目搜索,而是在更离散、更可解释的语言决策中试错。
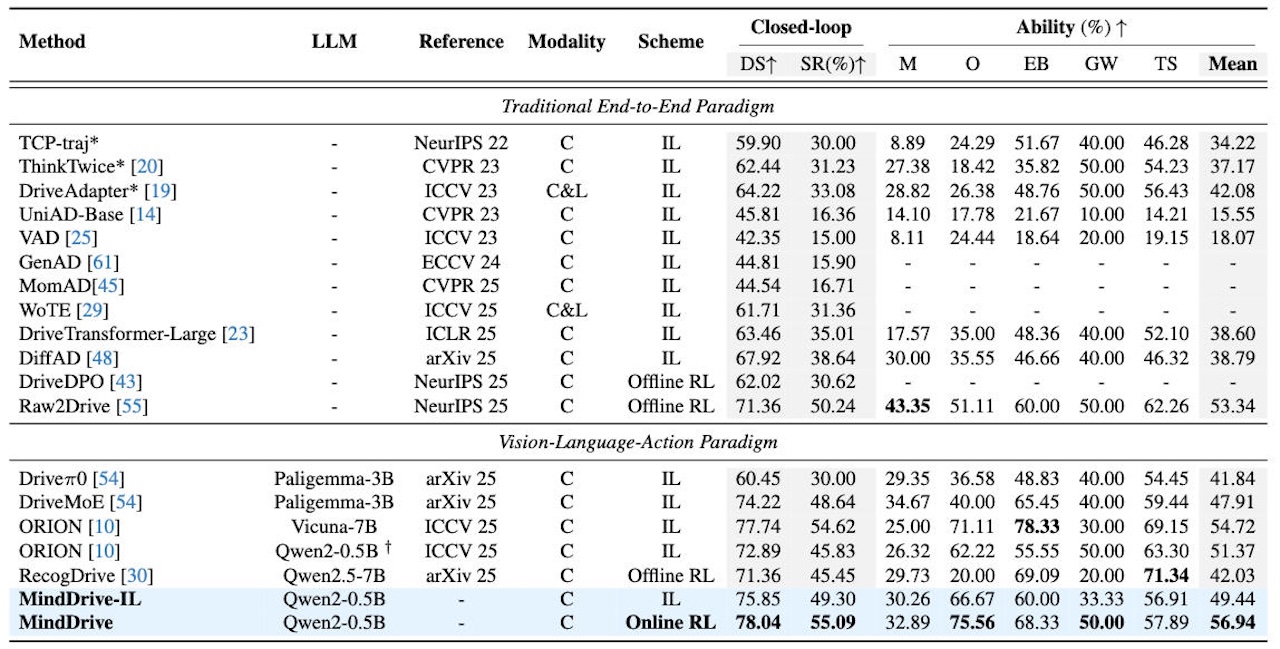
▲MindDrive跑分
论文结果显示,MindDrive使用轻量级Qwen-0.5B大语言模型,在Bench2Drive上取得Driving Score 78.04和Success Rate 55.09%。
2、DriveFine:规避路径驾驶风险
如果说MindDrive解决的是“模型如何学会更好地判断”,那么DriveFine解决的则是“模型判断之后,能不能先改一遍再执行”。
生成式自动驾驶规划有一个很现实的风险,很多模型像写句子一样一步步生成轨迹,如果前面某个判断偏了,后续轨迹就可能一路偏下去。
针对这一问题,DriveFine的答案是“先生成、再修正”。
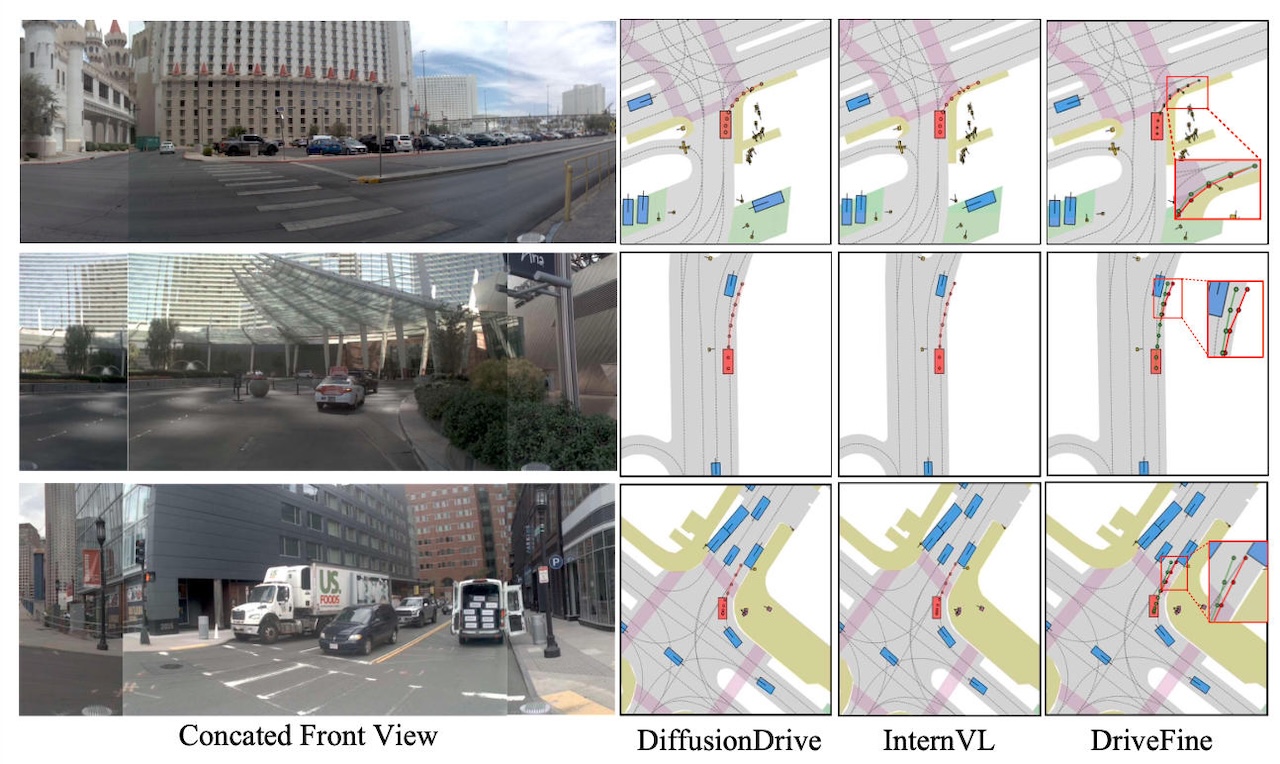
▲DriveFine路径决策对比
它提出一种掩码扩散式视觉-语言-动作模型,并设计了即插即用的块级混合专家结构:生成专家先给出初始轨迹,修正专家再对轨迹进行二次优化。
通过推理时显式选择专家、训练时隔离梯度,DriveFine将“生成”和“修正”解耦,既保留预训练模型已有能力,又给模型注入自我优化能力。
论文还设计了混合强化学习策略,在鼓励修正专家探索的同时保持训练稳定,并在 NAVSIM v1、NAVSIM v2 和 Navhard 等基准上验证了鲁棒性。
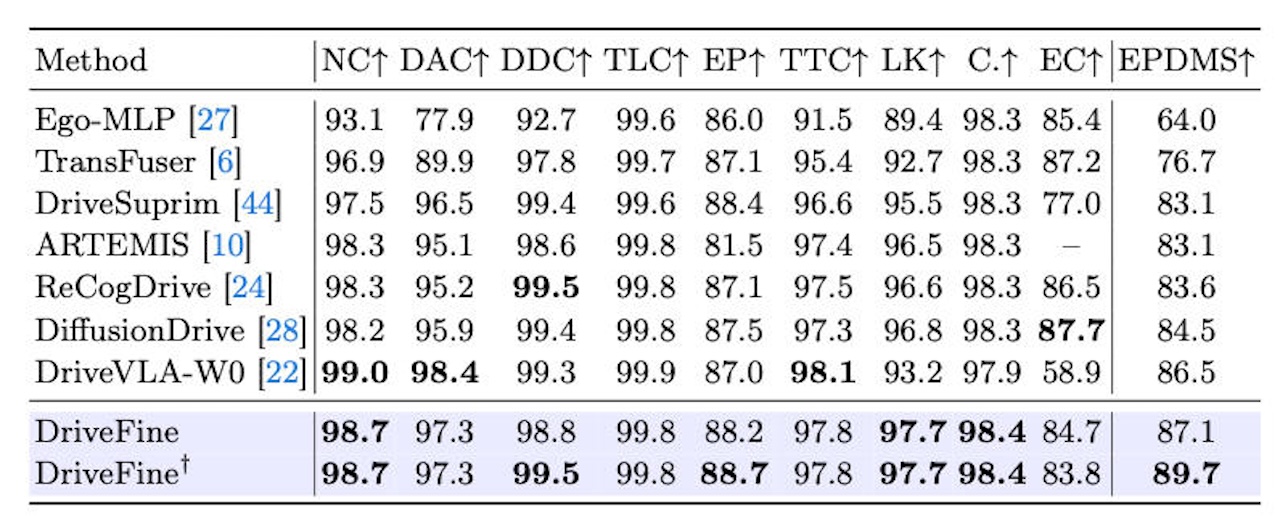
▲DriveFine跑分
DriveFine让模型内部具备“反思”能力,先给出一个驾驶方案,再检查它是否安全、平顺、合理,最后在真正执行前完成修正,这样进一步提升了自动驾驶的稳定性。
三、让模型不只学会“怎么开” 也知道“什么不能做”
世界模型解决“未来会怎样”,VLA模型解决“应该怎么开”,但对自动驾驶来说,还有一个更底层的问题,那就是模型是否真正知道,哪些动作看起来接近正确,实际上却很危险?
这正是BeyondDrive这篇论文的切入点。
过去很多端到端自动驾驶模型依赖模仿学习,也就是让模型尽量贴近专家轨迹。
但这里有一个容易被忽略的陷阱:离专家轨迹近,不等于安全。
毕竟,两条轨迹在几何距离上可能只差一点点,模型训练时的损失也差不多,但结果可能完全不同。
一条还能安全通过,另一条可能几秒后就会碰撞。
论文中指出,传统模仿学习默认“空间接近等于行为安全”,这会造成目标错配——相似的模仿误差,可能对应完全不同的安全结果。
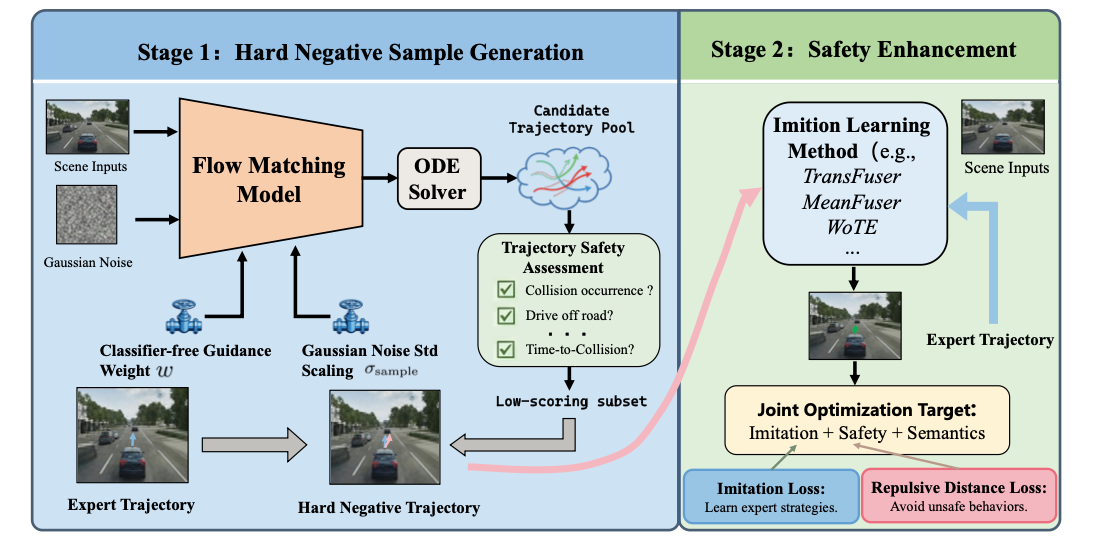
▲BeyondDrive架构
因此,BeyondDrive的主要工作就是让模型学会识别“危险的相似答案”。
它的方法可以理解成给自动驾驶模型建立一本“错题本”。模型不只看正确轨迹,还要看那些看起来很接近专家、但其实不安全的轨迹。
论文通过基于流匹配的负样本生成器,主动合成这类困难负样本;这些负样本在空间上接近专家轨迹,但在安全语义上存在风险。
随后,BeyondDrive 再用一种排斥距离损失,让模型一边靠近专家轨迹,一边远离危险负样本,从而在轨迹空间里建立更清晰的安全边界。
这个思路的价值在于,它把自动驾驶训练从“只学正确答案”,推进到了“同时理解错误答案为什么危险”,这对长尾场景尤其重要。
真实道路上的风险,很多时候不是那种一眼就错的动作,而是那些差一点就对了、但关键时刻会出事的动作。
比如贴着前车过近、在路口稍微偏向冲突区域、避让行人时留出的安全余量不够。
这些轨迹可能在训练损失上并不显眼,却决定了系统在闭环驾驶中的安全上限。
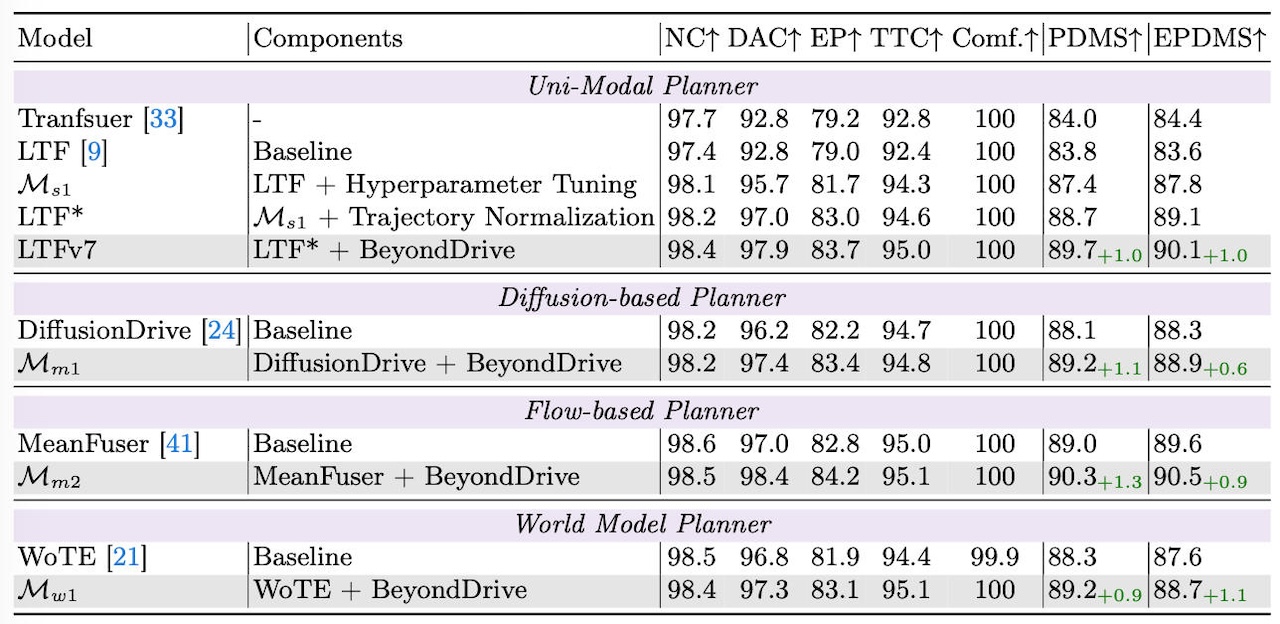
▲BeyondDrive跑分
从实验结果看,BeyondDrive可以迁移到不同端到端驾驶架构中,它应用在Latent TransFuser基线上,在NAVSIMv1闭环基准上达到89.7 PDMS,在MeanFuser + BeyondDrive跑分达到90.3 PDMS。
如此来看,BeyondDrive重新定义自动驾驶模型该学什么,安全不是只靠更接近专家轨迹就能得到的,模型必须显式知道:哪些选择虽然看起来合理,但已经越过了安全边界。
结语:小米自动驾驶再放大招
从这五篇论文可以看到,小米自动驾驶研究的重心在于搭建一条更完整的技术链路。
技术团队用世界模型预演未来,用视觉-语言-动作模型形成决策,用强化学习优化判断,用安全负样本划清边界,再用自我修正提升规划鲁棒性。
如此来看,自动驾驶的下一步,不只是让车“看得更清楚”,而是让车真正理解它所处的交通世界——知道未来可能发生什么,知道自己为什么这样开,也知道哪些选择必须提前避开。