








大家好,欢迎各位来到地平线策划推出的「你好,开发者」上海车展特别活动。我是地平线算法平台总架构师穆黎森,今天分享的题目是《详解BPU-智能机器人时代“最强大脑”》。

不同时代有不同的计算架构,在PC时代,核心的计算平台是CPU。CPU承载了PC时代人们所需要的所有的应用和计算。进入智能手机时代,仍然是以CPU为核心计算平台,但会更看重功耗、体积、成本。在云计算时代,一个非常核心的计算平台就是GPU。它提供了非常可观的计算密度和算力密度,可以非常好地支撑云端运行的各项业务所需的繁重计算任务。
 图一
图一到了智能机器人时代,我们认为其中非常核心的一个计算架构就是BPU (Brain Processing Unit)。可以看到,其中非常重要的一个形态和应用场景是自动驾驶汽车。
 图二
图二从汽车诞生之初,科学家和工程师从未停止过对于自动驾驶功能的想象和探索。早在几十年前,就有实验室做过从视觉输入到自动驾驶的实验,且局部Demo也较为成功。但是直到近期,作为一个普通的用户,我们才能真正感受到自动驾驶以及辅助驾驶应用的大爆发,大家逛一逛车展也能感受到。其中一个非常核心的原因,是终于找到了正确的处理物理世界层出不穷的配置方式,也就是用数据驱动来解决。
传统上的编程是用规则去实现,由专家把解决问题的规则翻译成机器可以理解的语言,进而形成计算机系统。这种方式其实不能很好地解决机器人时代的问题,无论是感知问题,还是现在看到的规控问题。因此,现在迫切需要一个计算平台来支撑智能计算架构2.0,不仅需要数据来驱动推理的系统,也需要去驱动软件的设计、编译器的设计,甚至包括硬件的设计。
 图三
图三自动驾驶系统与机器人系统一样,Pipeline都很类似。机器人首先要理解和感知周围的环境。那么对于车来说,需要知道自己去哪,需要知道前方的路况,并融合地图;接下来,需要规划到达这个目的地所需要follow的路径,最后去控制车辆。沿着规划路径走叫控制,这是一个非常传统的 Pipeline。
现在一个非常明显的趋势是Pipeline的各个环节都是不断的向数据驱动去靠拢。那么感知是well defined一个问题。计算机视觉其实是一个发展很久的领域,所以是最先被数据驱动的。但后面的环节我们也观察到一个几乎是不可逆的趋势,就是不断地提升数据驱动的比重,进而驱动系统实现进化。在数据驱动的技术发展趋势之下,也需要相应的由数据驱动的智能计算架构来支持各项计算任务的达成。所以拥有了智能进化能力的BPU——Brain Processing Unit,可谓是智能驾驶的“最强大脑”。
 图四
图四其实所谓的各种PU大家可能都听得比较多。Brain Processing Unit是针对机器人的应用场景而设计的。而机器人的应用场景就有很多的特点,比如说运行时的工况,如果用GPU来举例,它的batch size通常是1,输入的信号要及时处理和反馈,不会等到一个batch再处理。需要非常强大的 AI计算功能,这当然是最基本的。还需要非常完善的功能安全,这不仅是汽车行业的要求,更是保证自动驾驶安全性的非常重要的条件,因为自动驾驶是与人的生命安全息息相关。当然还有一些其他的特点,比如它是车载专用的,移动实时的,并且低能耗的,这也是区别BPU和其他的计算单元的一个重要的特性。
通过软硬结合的极致优化,地平线的BPU其实是在持续迭代的。首先,驱动BPU迭代的原初是算法。算法不断向前发展演进,并且要不断用算法去解决更复杂的问题,从感知到规控,那么我们就需要通过编译器不断去优化。我们的硬件设计其实得益于从算法到编译器的优化,持续去探索怎样的硬件平台能够更好地支持算法的运行,能够符合未来算法的趋势。
当BPU架构确定了以后,在这一代的BPU上,我们会让编译器和算法去做极致的优化,让算法能够发挥出在这一代BPU上极致的性能,达到一个最终的目标,就是所谓的效能,也即单位成本,可能包括功耗,包括实际花的钱,能达到算法的最终效果,这个效果涉及感知,也包括规控的效果。
BPU主要演进了三代,今天重点讲的是最新一代BPU®Nash。
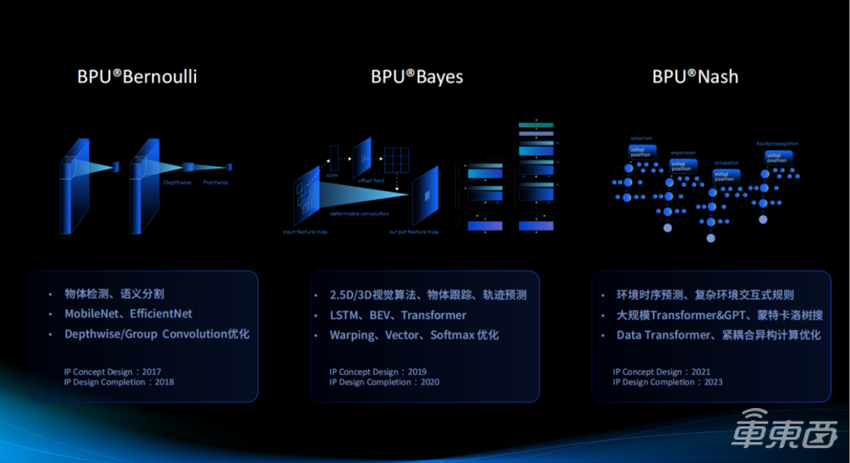 图五
图五驱动BPU架构迭代的因素,是源于我们对应用场景,以及应用场景背后的智能计算架构的深刻理解。最初,BPU是用来做一些感知的任务,包括基于前视的自动驾驶的一些功能。在这种情况下,需要支持的是相对稀疏的卷积。我们观察到高效率的卷积,像MobileNet,EfficientNet这样的一些结构,所以对于这些结构后面的算子也做了非常高效的支持,使得在BPU®Bernoulli架构下的芯片,可以以非常低的成本和功耗,达到和当时的主流显卡类似的一个感知的性能表现。
接下来是BPU®Bayes架构。在这个时代,我们发现汽车逐渐地走向了中央计算平台,不仅要处理前视,汽车周围各种各样的摄像头、各种Sensor也必须综合起来处理,才能够去应对高速上的各种各样路况。在这种情况下,我们发现背后的算法演变了。我们不仅要去做多摄像头融合,也需要去做不同传感器融合,也需要做时序的融合,才能对周围的环境做一个非常好的完整的建模。其背后的算法,我们也做了一个非常好的支持。比如在这个时代,Transformer崭露头角,所以也对这样的算法做了一个非常好的支持。对于背后的算子,比如Warping、Vector、Softmax,也做了很好的优化。
BPU®Nash架构是我们新发布的。作为中央计算平台,其实整个自动驾驶的链路,无论是感知还是规控,都需要用AI来驱动其进步。一个非常显著的趋势是,Transformer作为一个非常优秀的算法架构,可以将感知、规控等各种任务,统一到Transformer框架下;甚至之后可能一些大模型涌现出来的随机应变、举一反三的能力,也需要部署在车上。所以对于这类的算法,比如大规模的Transformer也做了一个非常良好的支持,包括这上面的搜索树。
纳什均衡,大家应该听过这个词。实际上,车在路上自动驾驶,特别是在城区,也是一种和他车、他人的博弈。我怎么样的行为会影响他人,他人什么样的行动会影响我,是一个交互博弈的决策过程,也需要我们做一个很好的支持。所以大家可以从应用的角度来看,应用其实是会变得越来越复杂,AI的任务也变得越来越复杂,不仅仅是从网络的规模,也从要处理的任务上。
在这期间编译器就成了一个非常核心的工具。那么,编译器的任务其实就是把我们算法开发人员开发出来的神经网络模型,能够转化成可以在我们计算平台、芯片上运行的一个指令序列。转化的过程其实有很多可能性,最终的指令序列也许都是和最初的神经网络在语义上是等价的,但运行效率、运行的延迟、FPS会千差万别。所以,编译器其实是解决这样的一个问题:在这样大的一个搜索空间里,找到一个最优的在BPU上运行的一个指令序列。而这个问题,随着网络规模的不断扩大,问题变得越来越复杂。
所以,第一代编译器的技术是这种启发式搜索加动态规划。它其实是相对传统的一个策略,好处是可以把我们一些编译器专家的Know-How,放在我们整个搜索的过程中去指导搜索,当然整个空间还是非常巨大的。在其中,也是需要这样的一些启发知识,来指导我们进行搜索,最后可能会找到一个解。这个解应该是性能还不错的解,但可能并不是最优解。
第二代编译器引入Policy Network。所谓的 Policy其实就是一个AI驱动模块,能够以人或专家写的规则,将最后找到的解当做一个专家的演示,然后让Policy Network去学习专家知识。这样Policy Network就可以直接推断在当前节点的下一个合理选择是什么,这就起到了一个非常好的剪枝作用。这就像在围棋里,围棋大师会有所谓的棋感,知道落到这个子大概是可以的,那个子是很不行的。如果没有这样的棋感,下棋可能需要考虑非常多的步骤;如果有这样的棋感,我们的搜索会更加有效率,这样对比第一代策略就大大缩减了搜索时间和编译时间。
第三代编译器就引入了Value Network和蒙特卡洛树搜。不管是第一代还是第二代编译器,都有一个问题,就是也许会无法逃脱局部最优解。这里我们可以看到一个随机的过程,通过Policy和Value的判断,具有一定的随机性,通过这种蒙特卡洛树搜的框架,可以跳出局部最优解,并且更加有可能寻求到全局的一个最优解。在编译时间不会过多增加的情况下,能够提升最后找到的模型的指令序列的运行效率。
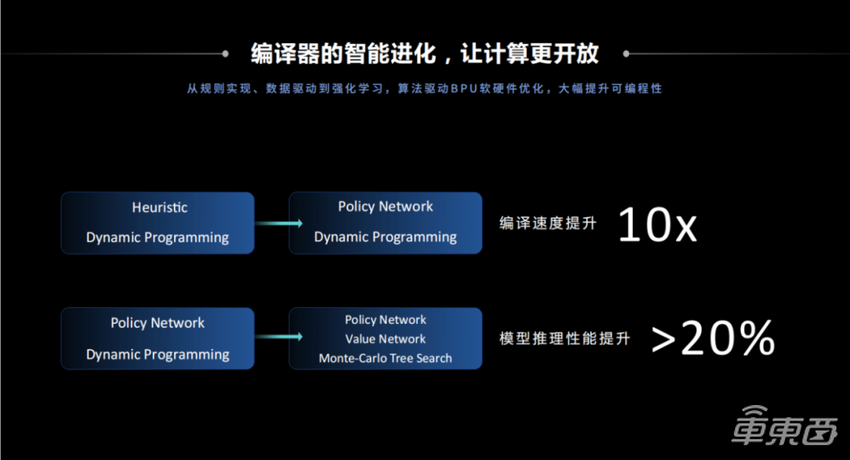 图六
图六最终,就会达到这样的一个收益:通过引入Policy Network这种类似于专家的网络,能够大大缩短模型编译的时间。再通过引入蒙特卡洛树搜,强化学习框架下的一些技术,可以使在编译时间不会大大增加的情况下,编译模型的性能至少提升20%。随着算法的发展,编译问题会变得越来越复杂,可以观测到的收益其实会越来越高。所以,编译器为算法开发者提供了一个非常强大的武器。
纳什架构面向开发者提供了一个更加友好的武器,就是对于先进的编程模型的支持,包括列出的DSL和HPL。之前,我们通常是针对某一些业界的所谓指令集做优化和支持,但我们发现这样做对于面向开放的算法,效率也许不高。因此在上层提供了DSL、在下层提供了HPL给开发者们,让他们能够以更高的效率去进行新的算法支持。这不仅仅是指AI模型中新的算法,还有整个系统里面,乃至整个Pipeline上的。我们传统上可能认为这个计算是属于模型的,而下一个计算通常用CPU对模型的输出进行一些处理。在整个系统中,我们发现它会不断地在BPU和CPU的workload中间切换,无论是调度复杂性,还是数据传输,代价都是非常高的。
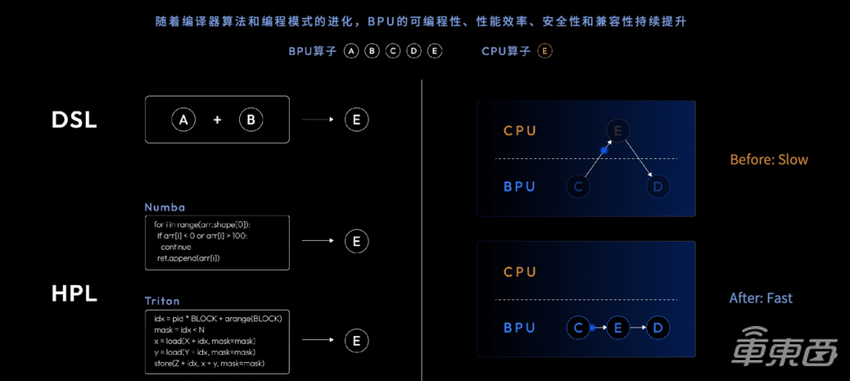 图七
图七通过这种DSL和HPL、高层和底层的一些开放的编程接口,可以做到让开发者把自己在系统整个Pipeline上的workload向BPU下沉。这样无论是整个系统的延迟,还是系统调度的复杂性,都会有非常明显的收益。当然,我们也会在用户体验上来做更多优化,支持用户可以用C语言,甚至像Python这种高层的编程界面,方便他们在纳什架构上去做编程。
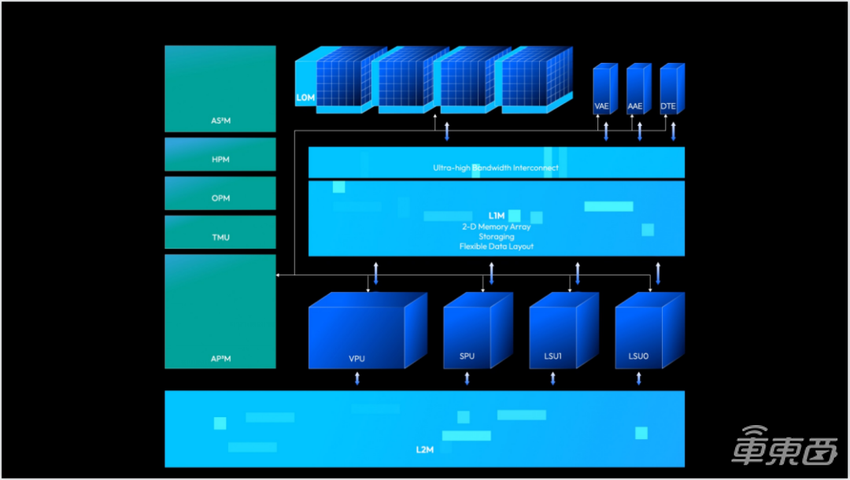 图八
图八之后简单介绍一下我们几代 BPU架构。第一代其实是个相对简单的架构,对刚才提到的稀疏卷积做了比较好的支持,有一些简单的调度。进化到第二代时,支持的算子会更多,而且加入了一定的异构计算的支持,也加入了一些对Power&Perf的监控模块,并且支持了ASIL-B。第三代纳什架构,可以看到它更复杂。直观上可以看到对数据处理这部分明显变复杂了:不光是支持多级存储,也有数据变换引擎,灵活支持transformer细小算子,同时有多脉动立方加速引擎,对计算本身做了支持和加强,另外在Monitor等各种方面的一些功能性的feature,也做了一个非常完整的支持。
 图九
图九以上就是最新一代的BPU纳什架构,这里列举了8个创新点。可以看到,其中很多都是以数据为核心的,包括存储架构、数据变换引擎等。我们观察到,未来特别是大型Transformer网络,对于数据搬运和访问的优化需求,其实是非常多的。同时,我们增加了对于浮点向量加速单元的支持,这对于提升整个用户体验,尤其是未来比较复杂的大规模Transformer网络,从训练到在芯片上部署的用户体验是至关重要的。将来我们会更加友好地支持用户自己训练的浮点模型,使其可以更方便地在我们芯片上做部署。针对这种Transformer计算的特点,我们会针对性地优化它的功耗。这其实深入到了硬件实现的一些底层,包括Feature Activision响应、比特分布响应。我们会仔细分析这些响应,并且针对这些响应的动态特点去做针对性优化。
这里还想提两点:一个是紧耦合异构计算,刚才提到的这种交互式的蒙特卡洛树搜。我们在路面上跟他车进行博弈时,其实需要各种各样的异构单元支持,所以希望整个蒙特卡洛搜索树都能够在BPU上运行;二是虚拟化,纳什架构未来会支撑中央计算平台。而一个计算平台会支撑各种各样的应用,包括但不限于自动驾驶、座舱等领域。
 图十
图十我们最终追求的一个目标是希望用户可以感知到,我们的系统在满足某种精度的FPS下运行时,最终到底花了多少的代价,包括实际花费成本和自身的功耗。为了达到最终用户可感受的最优解,我们需要在三个方面做极致的优化:
-
-
硬件层面,优化理论峰值的计算效能; -
算法层面,要去优化算法的效率; - 软硬结合编译器和架构层面,去优化整个利用率。
-
这三个方面并不是说三群人各自把各自的工作做到最好,而是通常是一个联合优化的问题。有时是在优化硬件的时候,需要编译器和算法的同学一起参与;有时是在优化算法的时候,需要编译器和硬件的同学一起参与,最终才能达到真实计算效能的最优。
 图十一
图十一刚刚聊完的FPS就是我们在这一代征程5芯片所能达到的一个计算效能。关注地平线的同学可能会知道,这个图已经放过好几次了,第一次放出应该是两年前,当时征程5刚发布时是1283 FPS;一年前这个数字更新为1531FPS;今天这个数字变成1718FPS。这都得益于做编译器和算法的同学,在征程5芯片发布以后不断地优化,最终达到了一个越来越高的性能。最终,这些性能会转化成在车上体验到的安全性、舒适性等。
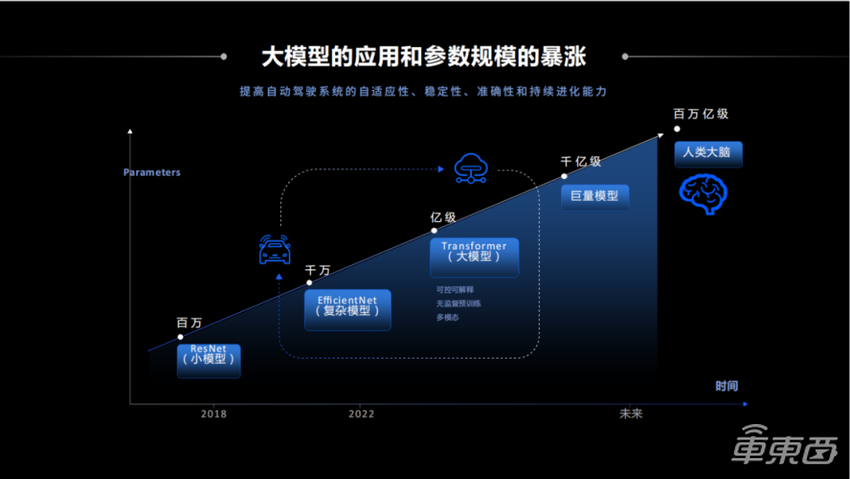 图十二
图十二对未来车载计算的一个预测,可以看到征程5到今年可以支撑千万量级的复杂模型,并且支持多摄像头融合、支持时空融合。纳什架构瞄准的是下一代Transformer大模型,那么无论从模型规模还是计算架构上来讲,都有一个比较大的提升。
在未来,我们认为车载的计算规模会进一步扩大。因为可以观察到一个明显趋势,现在比较大的模型已经涌现出一些通用人工智能的能力,可以举一反三,可以和人很友好地交互。这方面的能力,我们判断最终是会用到车上。一个人进驾校到学会开车可能几千公里就够了,一个车的系统可能见过百万千万甚至上亿公里的数据,但至今还没有达到人的开车水平。像人一样聪明地开车这件事情,我们认为一个可行的路径是把未来大模型的能力布署到车端,让车更聪明、能够举一反三。用专业术语就是泛化性更好,让我们能够去以更聪明的方式应对层出不穷的case。
在纳什这一代架构下,其实已经可以很好地支持端到端的Transformer网络,我们也认为这是一个很明显的趋势。举一个例子,我们发表在CVPR的Best Paper Candidate,提出了这样一套算法架构,可以从感知到最后的结果,整个都是用Transformer处理。多个摄像头的历史信息融合也是用Transformer,这是编码端。在解码端,我们是把各种任务,包括感知、预测,甚至于规划的任务,转化成所谓序列生成的任务。Transformer网络就可以去做这样的感知任务,可以看到会有对周围地形的理解、对他车行为的预测,也会对有自车行为的预测。这其实就是规控的一个Candidate。所以,它其实是一个非常优雅的架构。
 宋巍,地平线软件平台总架构师
宋巍,地平线软件平台总架构师 图十三
图十三前面讲到,我们现在的这套算法结构,它会是一个面向Software2.0数据驱动的软件体系。首先我们要看一下在数据方面会遇到哪些问题?
在这样一个系统架构和算法结构下,是高并发、多传感器和多任务调度的异构系统。我们期望的自动驾驶是一个确定性的系统,但实际在系统中,它存在着非常多不确定性。如果我们需要一个确定性系统的话,就需要有确定性的时间。时间同步就是我们在这个系统里要做到确定性的第一个点。
刚才谈到在BPU方面做了很多软硬结合的相关工作,其实在我们SoC的设计方面同样也有很多软硬结合的工作。
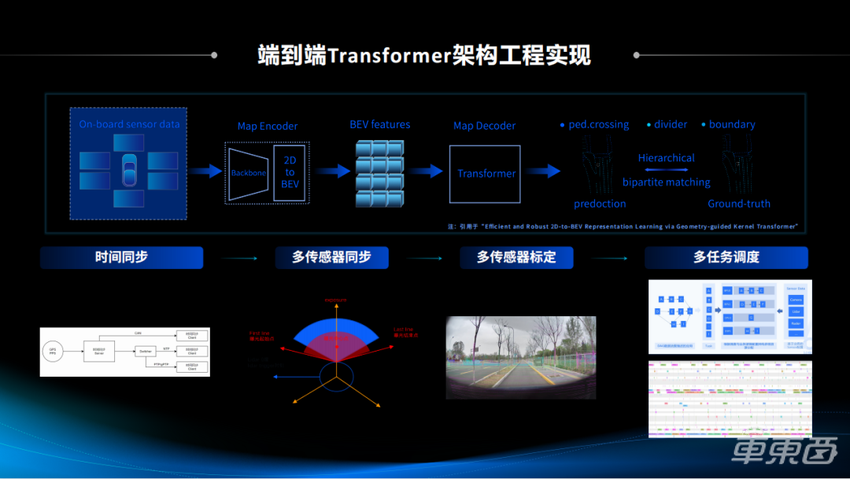 图十四
图十四在时间同步方面,除了传统的一些时间同步的软件系统,我们也在硬件的设计方面提供了很多基于硬件的PPS,然后把时间通过硬件的方式直接替换到我们的计算器,从而让时间同步更加的精准,更加的准确。
在单SoC中,时间同步也有很多的不确定性,比如GPS信号。当通过一个隧道的时候,往往通过隧道之后,我们的时间有可能会飘,那如何去解决这些时间的问题?然后,在多SoC以及多域之间,时间体系又是如何对齐的?这些都是需要去解决的问题。
当解决了时间问题,下一步我们就需要解决时刻问题。对于多传感器的同步,需要解决比如摄像头的曝光同步问题、摄像头的时刻问题。对于摄像头的时刻,在SoC的设计的过程中,我们也有软硬结合非常重要的一些设计。对于Sensor来说,它往往会有一个曝光的启动时刻,以及一个它的数据流的传输时刻。
这一点在SoC的硬件设计过程中,也是通过软硬结合的方式,通过硬件去把曝光时刻打到图像的时间戳上,从而让多传感器的时间能够更好的进行同步。
在一个异构系统当中,除了多路的摄像头,也有多个激光雷达。对于激光雷达来说,摄像头对于自动驾驶系统而言是一个rolling shutter的,它的曝光时间是有一个确定时间的。对于激光雷达来说,有各种各样的扫描方式,可以是机械式激光雷达、半固态的旋转镜或者Flash等扫描方式的激光雷达。为了让激光雷达点云和Camera更加匹配,同时也要解决激光雷达的相位差问题。在我们软硬结合的SoC设计上,也需要把相位差的同步考虑进去。
然后,在时间和时刻的问题解决之后,下一步要解决的是不同传感器之间空间的一些问题。我们有Multi-Camera,也有Multi-Lidar,我们需要在空间中对这些传感器进行一些calibration,让他们安装的位置、方位能够很好的与我们的车身坐标系形成一个统一。
当谈BEV的时候,我们在BEV的中融合是一个feature级的融合。当把不同传感器的feature投映到BEV空间时,如果空间的calibration不是一个精度(特别是对于这种BEV),它往往会比传统算法对这种calibration的精度要求更高,可能会到一个0.1度的级别。在这个基础上,我们对calibration的要求也会更高,这样我们才能够得到一个准确匹配多维、多空间的feature融合的效果。
解决了时间和空间的问题之后,在这样一个复杂的异步高并发的系统里、在实际的软件开发过程中,我们需要很强的调度能力。在一个异步高并发的系统中,我们如何通过调度把一个不确定性的系统变成一个确定性的系统?这就需要我们有一个确定性的调度能力——全局调度能力。往往开发一个复杂的自动驾驶系统时,我们的系统可能会存在多个进程,单SoC内可能会有多个进程,也会有多SoC,还会有多域、跨域的协同工作。
当谈整个自动驾驶系统时,我们的软件系统往往需要优化的是一个端到端的延迟,可能并不是某一个任务的单点延迟。当去优化整个端到端的延迟时,我们需要有全局的思考。在不同时间、不同时刻、不同任务的体系下,如何把我们的任务调度按照期望的顺序、期望的时间,达成期望的结果。为了完成这样的调度,同时需要我们有很好的任务Profiling机制。多任务调度需要我们在每一个任务中有Profiling的执行时刻,有它编排的顺序,同时需要有对应的工具,能够把这些Profiling的结果通过一些自动化编排或者人工编排的方式达成异步高并发的确定性。
当解决了所有这些数据和调度问题之后,我们才刚刚开始为我们的算法架构准备好基础的数据能力。
在端到端的过程中, BEV feature实际上还有时间融合的过程。时间上的融合其实就是一个多帧的持续关系,从而达到时空融合。如何完成这个时空融合,首先我们需要获得一个高精度、高清的车辆自身的ego-motion。一般我们会评价ego-motion,比如说100米的距离,它的ego-motion误差要小于一米,比如说每秒的一个角度误差小于0.1度,我们如何来完成这件事情呢?
计算ego-motion往往需要车辆原始底盘的信号,而原始底盘的信号需要信号矩阵去解析,不同车型的信号矩阵也是不一样的。我们也可能会需要IMU和GPS的数据。这些数据都是高频、小数据、高并发,而在自动驾驶的域控里,这些数据往往是连接到一个MCU网关,整个数据链路往往也非常的长。从车身信号到高安全等级的MCU,对这些信号打上时间戳,然后通过数据链路、通过SPI或者以太网,到计算核OS里的Kernel,再到Driver 、HEL,最后到应用层的Library,数据链路是非常长的,而往往在自动驾驶的开发过程中,数据链路是遇到问题最多的地方,而我们对这个数据链路延迟的要求非常高。如果数据链路的延迟过高,意味着ego-motion的延迟可能无法正常的让BEV完成一个时空的融合。
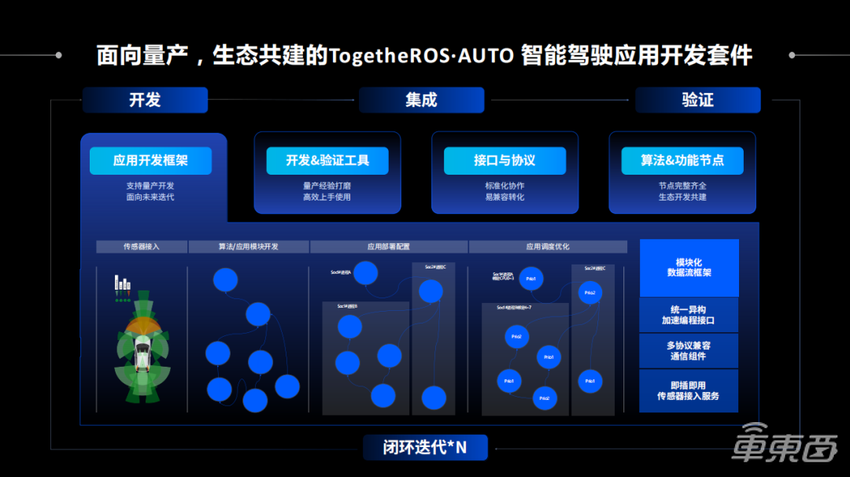
在这个基础上,我们需要对整个数据链路有一个很强的确定性的要求,然后去解决它的确定性问题、诊断每一个信号的正确性。为了解决这些问题,地平线在这次的车展发布会中发布了TogetheROS·AUTO、智能驾驶应用开发套件,同时我们会把开发、集成、验证三位一体地统筹起来。
 图十五
图十五我们将会提供应用开发框架、开发验证的工具,接口与协议、以及算法功能节点,这都是为了解决我们刚才提到的整个自动驾驶在量产化过程中遇到的所有工程化问题。解决这些问题其实也是为了提高我们每一个自动驾驶开发者的开发效率,因为这些问题不解决,每个人都会面临相同的问题。同时我们也会和不同传感器的供应商,和功能软件以及OS伙伴,一起去持续循环迭代,提升系统的易用性和整体性能。
首先,TogetheROS·AUTO智能驾驶应用开发套件会提供应用开发框架。刚才提到我们对传感器会有很强的性能要求,我们不仅要求它的时间时刻,还要求它的空间calibration都是非常精确的,同时需要对传感器具有很强的诊断能力。因为对于一个自动驾驶来说只是时间和空间正确性可能还是不够。因为传感器,比如摄像头,因为它是高速的接口,往往在实际的道路过程中,有可能会受到一些电磁干扰的影响,有可能会突然出现一些传感器失效,我们需要能诊断出这些失效情况。
 图十六
图十六对于一些极端天气,比如下雨、下雪,传感器也有可能会被极端天气导致的异常脏污影响,从而造成传感器遮挡和模糊,我们需要把传感器的这些状态体现出来。除了提供传感器的模块,我们也需要提供整体的调度框架,来解决异步高并发的调度问题,然后解决调度编排、调度顺序问题,同时还要解决灵活的软件部署问题。我们的模块是部署在一个线程级别or进程级别, SoC内、跨SoC还是跨域,特别是面向未来舱驾一体整体的整合过程。
同一套软件框架在跨域的配合方面如何高性能的去达成配合,也是非常重要的一个点。为了能够让所有模块之间的配合更加顺畅,我们会把接口、协议以及对应的reference的一些节点提供出来。同时,为了提高开发效率,我们也会提供可视化的设计工具。
大家在自动驾驶的开发过程中,都会遵守V model,从需求到整体的架构设计,然后到软件架构设计、软件实现、单元实现,再到V model的右半边,及我们所有逐级向上的验证过程。只有从设计到实现、到验证,完整地和开发过程结合起来,它才会是一个可追溯、可被量化的过程。
通过提供良好的开发工具,我们去Profiling每一个开发的节点、每一个通讯节点、它的时间占比、调度顺序,然后通过Profiling结果提供一些编排能力,以及基于接口协议,我们也会提供对应的数据展示工具,以及面向自动驾驶的可视化工具。讲到可视化工具,刚才有提到,一个自动驾驶的车辆会有非常多的传感器以及非常多的数据类型,那么对于一个可视化工具,如果我们不对它做深度优化,其实给电脑性能带来的卡顿是非常严重的。所以这在展示的过程中其实是一个非常重要的点,这有利于我们去展示产品的效果,有利于在我们开发的迭代过程中看到效果。
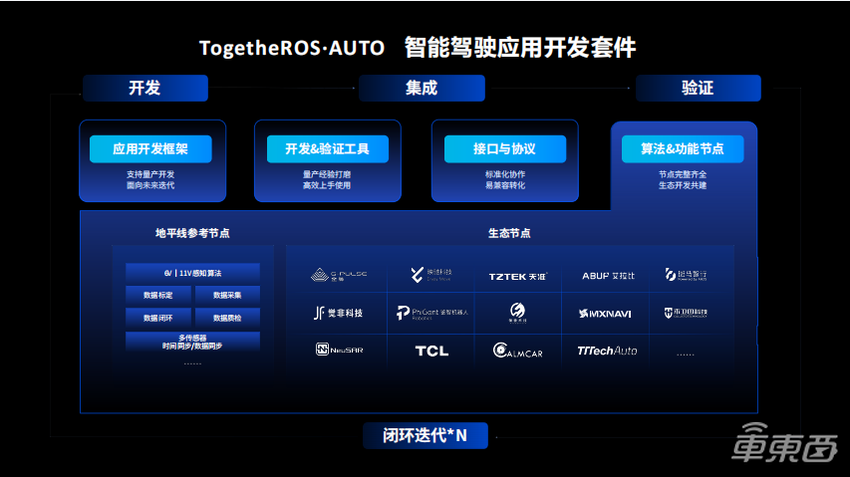 图十七
图十七刚才有提到地平线会发布地平线的参考节点、所有Sensor的过程、车身的信号通讯,以及对应的一些基础算法模块,比如ego-motion,来保障链路的延迟和链路的正确性。同时,我们也会和我们的生态合作伙伴一起共建智能驾驶的开发套件,提供不同算法的节点,比如感知、定位地图或者规划控制,以及整体底层的硬件系统。
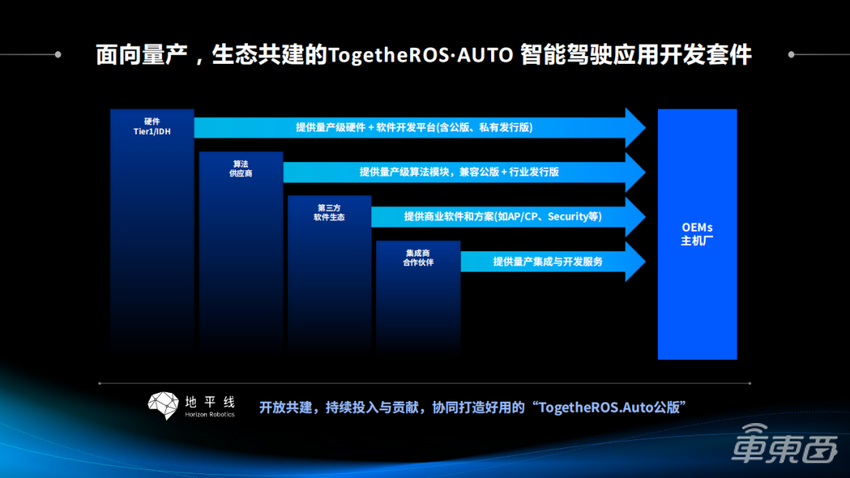 图十八
图十八面向量产,如果是量产的开发过程,我们可以从最左面看到,从一个硬件、算法供应商开始,到最后的OEM的路径,是非常长的。其实,硬件对于一个主机厂来说,只提供了硬件和底软。对于算法供应商来说,每一个算法供应商可能会针对对应的硬件做对应的一些开发。
如果我们的硬件没有一个很成熟的标准体系的话,其实不同的硬件去适配的时候会遇到非常多的问题。然后会有一些第三方的软件生态,包括底层的比如说 AP或者CP,我们会去和他们去做一些深度的合作共赢。面向集成商的时候,如果大家能够一起去共创,其实他到OEM的距离就会大大的缩短。他不需要从硬件开始去熟悉每一个硬件平台、去熟悉每一个算法模块,而是大家都在一个开发套件下、一个标准下,能够完成对应的一些开发工作。
基于地平线的征程5芯片,其实地平线现在已经有一个所谓的“生态货架”的概念。可以看到,我们的硬件域控,现在有这些不同的生态合作伙伴,以及我们的软件开放平台,也有非常多的合作伙伴向我们提供对应生态的一些节点和对应的算法能力。在地平线的展台,有非常多实体的域控展示,以及生态合作伙伴提供的一些共建的算法模块,我的分享就到这。“征程与共,一路同行”,希望基于我们的软件开发平台和解决方案,能够共同构建我们的整体生态,感谢大家!

