车东西(公众号:chedongxi)
作者 | Janson
编辑 | 志豪
4B参数打10B参数?!小米最新辅助驾驶模型OneVL开源。
车东西5月14日消息,日前,小米技术团队正式发布并开源Xiaomi OneVL,这是一套面向自动驾驶轨迹预测的“一步式潜空间语言视觉推理框架”。

▲小米最新自动驾驶论文
论文中,OneVL在多个基准上实现了一个很有看点的结果——不仅推理速度快,精度还高。
在NAVSIM(一种自动驾驶规划评测基准)上,OneVL的跑分达到88.84,高于显式推理链的88.29,延迟则几乎等同于只输出答案的AR Answer的4.49秒。
更值得一提的是,在英伟达的Alpamayo-R1基准测试中,OneVL作为4B参数模型,在ADE平均轨迹误差指标上取得2.62m,优于10B参数级英伟达自家Cosmos-Reason的2.86m。
可以说,小米OneVL一举实现了用更小模型反超大模型的技术指标。
从实现思路上来看,这篇论文真正要解决的问题很直接,过去模型要想“想得清楚”,往往得先生成一大段CoT推理文字,但在自动驾驶场景里,逐字生成推理链会带来明显延迟。
小米OneVL的思路则是,训练时让模型学会解释、学会预测未来画面,推理时则把这些思考压缩进少量latent token,一步激活,直接输出轨迹。
此外,通过作者阵容也能看出这项工作在小米汽车技术体系中的位置。
名单中既有小米汽车首席科学家、自动驾驶与机器人部VLA负责人陈龙,也有小米具身智能与自动驾驶统一模型MiMo-Embodied的核心作者郝孝帅,以及小米汽车自动驾驶负责人叶航军等关键人物。
可以说,OneVL是小米汽车在端到端自动驾驶大模型、VLA和世界模型路线上的一次集中技术展示。
一、小米OneVL怎么做? 压缩步骤降低延迟
要理解小米开源的OneVL,先要理解它为什么不是简单的“把CoT藏起来”。
过去自动驾驶VLA模型引入CoT,主要是为了让模型在输出轨迹前先完成一段显式推理,从而让系统知道当前道路边界在哪里,前方有没有车、行人、锥桶,接下来应该保持速度、减速、变道还是转向。
很明显,显式CoT的好处是可解释,也能提升轨迹预测质量,但问题是,它需要一个token一个token自回归生成,推理链越长,延迟越高,这对实时部署并不友好。
为了解决这个问题,latent CoT诞生了,通过把原本显式写出来的推理过程压缩进隐空间。
目前行业中主流的COCONUT、CODI、SIM-CoT等方法都属于这个方向。
但小米团队认为,这些方法主要面向语言推理任务,压缩的是“语言描述里的抽象语义”,而自动驾驶轨迹预测真正依赖的是道路几何、目标运动、环境变化等时空因果结构。

▲几种CoT范式的比较
换句话说,这样的做法只压缩语言,并不等于理解真实道路世界。
因此,OneVL的关键改动,是把“未来世界会怎么变”也压进模型里。
论文中的OneVL主干基于Qwen3-VL-4B-Instruct,输入包括前视图像、车辆状态、导航指令、历史轨迹等信息,最终输出未来轨迹。
它在模型中设计了两类latent token(潜在词元)。一类是language latent token,用来承载语言层面的隐式推理,另一类是visual latent token,用来承载视觉和时空动态信息。
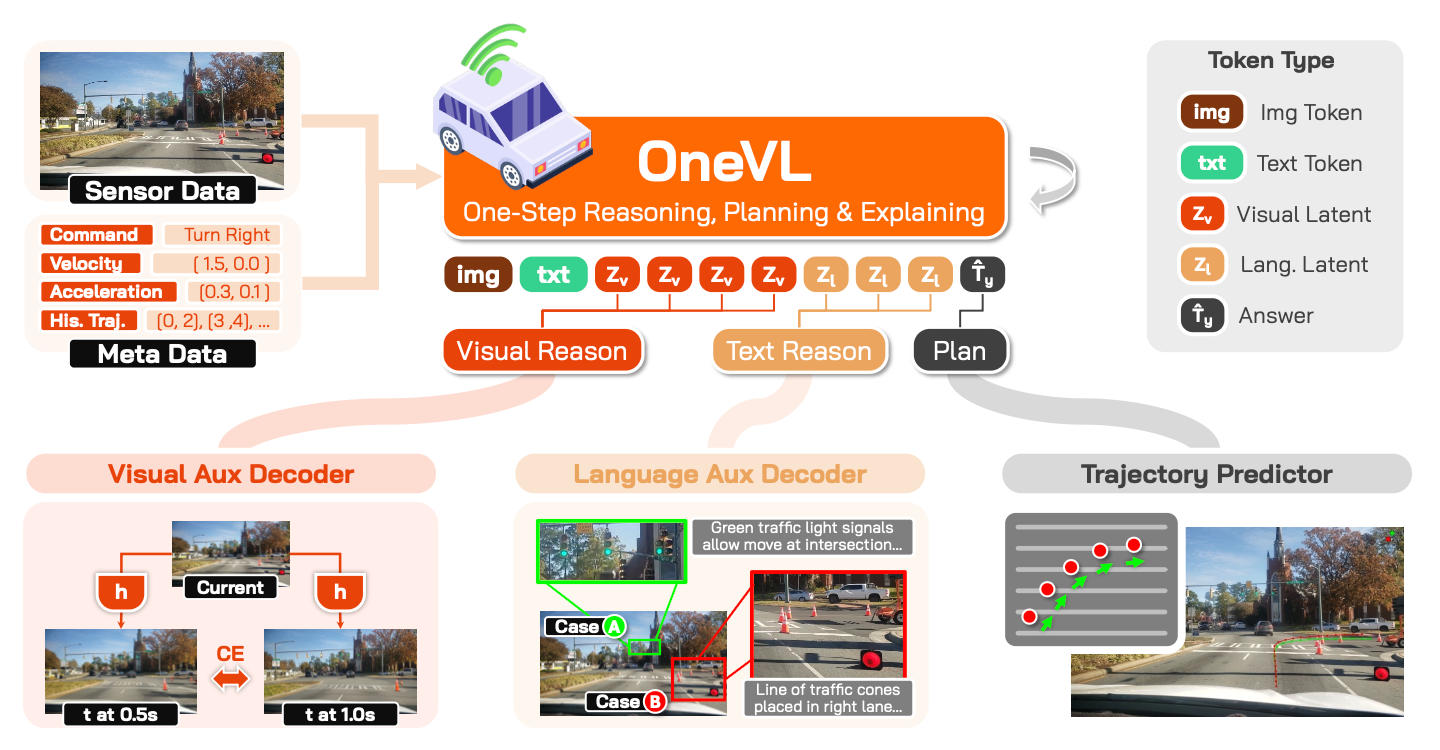
▲小米OneVL架构
训练时,OneVL会接上两个辅助解码器。
第一个是语言辅助解码器。它的任务是从language latent token中还原人类可读的CoT文本,比如解释模型为什么判断前方应该减速、为什么要保持车道、为什么要向左避让。
这个模块让latent token不只是黑箱向量,而是可以被“翻译”成人能理解的驾驶理由。
第二个是视觉辅助解码器。它的任务更关键,从visual latent token中预测未来帧视觉token,也就是让模型预判0.5秒和1.0秒之后画面可能是什么样。
这两个模式被并称为一种world model auxiliary,即训练阶段的世界模型辅助监督。
它要求模型不只是知道“前方有车”这个语义标签,还要理解车辆会怎么动、道路结构如何延展、障碍物和环境会如何变化。
这也是小米OneVL和传统latent CoT最大的区别。
传统latent CoT更像是把“文字推理”压缩成隐变量,小米OneVL则是把语言推理+未来视觉变化+轨迹规划放在一个框架里联合训练。
语言监督负责让模型说清楚“为什么这么开”,视觉监督负责让模型学会“世界接下来怎么变”,轨迹监督则负责最终“应该怎么走”。
如此一来,在真正上路时,它不需要把这些推理逐字说出来,而是直接给出规划结果。

▲小米OneVL在部分场景下的推理结果
训练流程上,OneVL也不是简单端到端硬训,而是采用了分阶段策略。
在初始阶段,模型先对视觉辅助解码器做自监督预训练,让它学会根据当前帧视觉特征预测未来帧。
这样做是为了避免一开始latent token还没有有效信息时,视觉解码器就被迫完成困难任务,导致训练不稳定。
随后,OneVL采用了三步训练,第一步,先训练主VLM做轨迹预测。这个阶段的重点是让模型先学会“怎么开”,同时让插在输出里的latent token开始承担“思考占位符”的作用,逐渐存下和驾驶决策有关的信息。
第二步,先固定住主模型,只训练语言和视觉两个辅助解码器。语言解码器要学会把这些latent token翻译成文字解释,视觉解码器要学会把它们翻译成未来画面。这样做的好处是,两个解码器面对的是一个相对稳定的“模型大脑”,不会一边读信号、一边信号本身还在剧烈变化。
第三步,再把主模型和两个辅助解码器一起训练,让轨迹预测、语言解释、未来画面预测三件事互相对齐。
最终,latent token同时可以承载“怎么开”“为什么这么开”和“接下来会发生什么”的压缩表示。
训练时使用的语言辅助解码器和视觉辅助解码器,在推理时都会被丢弃。
而这,也是推理阶段是小米OneVL速度提升的关键。
所以,OneVL的核心不是“不推理”,而是把推理从显式长文本,压缩成一步式潜空间激活。
二、小模型能打大模型 又快又准
通过一系列优化,小米OneVL性能得到了明显的提升,但具体怎么样,还是要用跑分来说话。
OneVL的成绩可以用一句话概括就是,它不是单纯跑得快,也不是单纯跑分高,而是在“接近不思考的速度”下,做出了“超过显式推理”的精度。
过去自动驾驶VLA模型往往要在速度和推理能力之间做取舍,如果模型直接输出轨迹,速度确实快,但少了推理过程,精度和复杂场景泛化可能不够。
如果让模型先生成一段CoT推理,再输出轨迹,精度通常会提升,但速度又会明显变慢。
OneVL做到了一种既要又要:精度高,速度快。

▲四种基准测试的表现
论文在NAVSIM、ROADWork、Impromptu、Alpamayo-R1四个基准上做了测试,可以理解成四类不同“考场”,常规轨迹规划、施工区复杂道路、非结构化长尾场景,以及复杂因果驾驶场景。
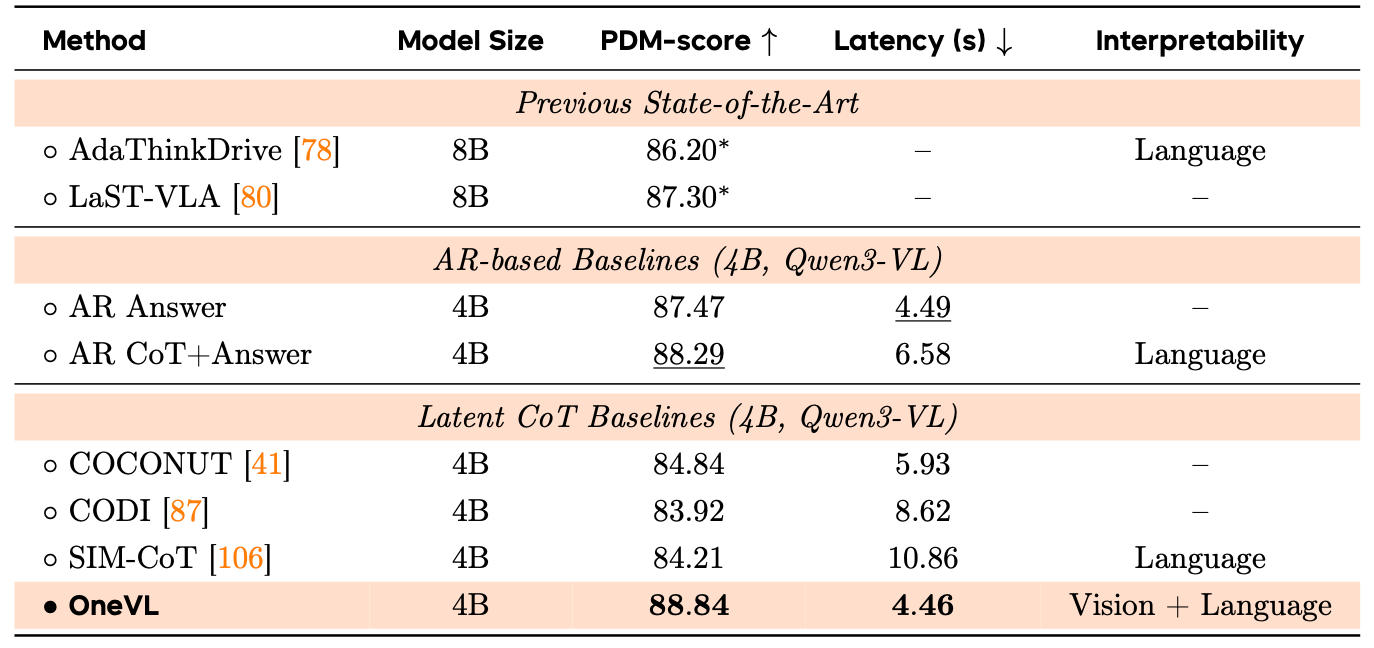
▲NAVSIM性能对比
结果也很直接,在NAVSIM上,OneVL跑分达到88.84,超过直接输出答案的AR Answer 87.47和显式AR CoT+Answer 88.29。
同时延迟只有4.46秒,几乎等同于AR Answer的4.49秒,明显低于显式CoT的6.58秒。
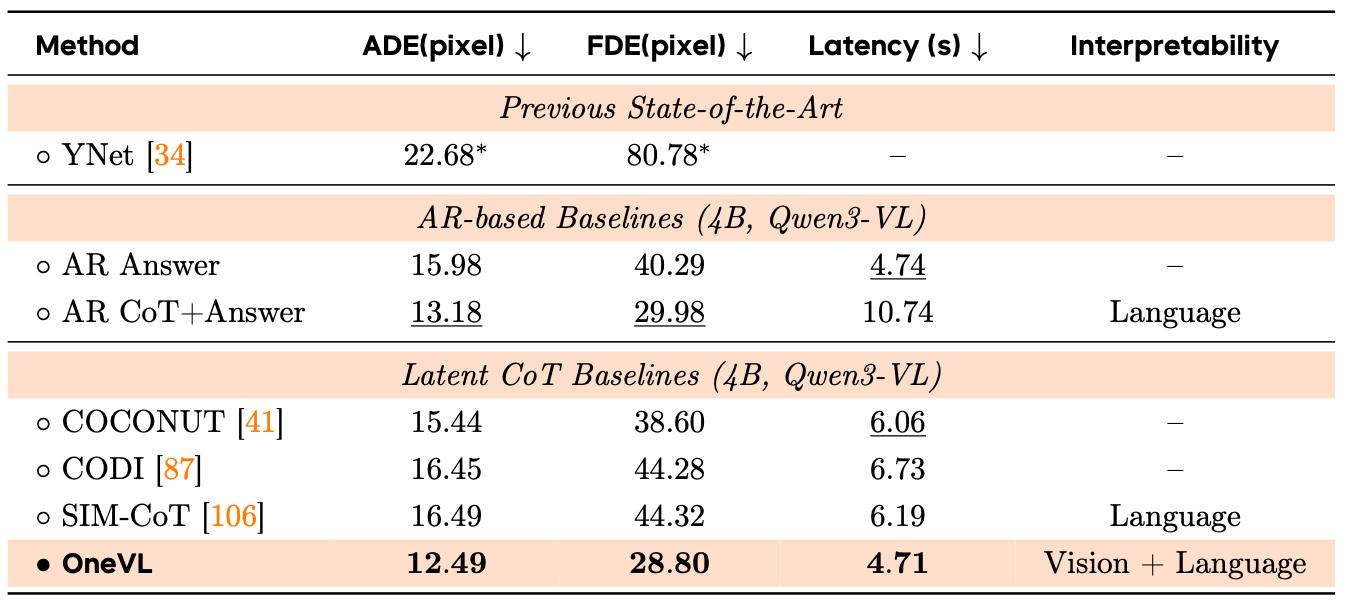
▲ROADWork性能对比
在ROADWork这种施工区这种有锥桶、临时标线、施工车辆和封闭车道的复杂场景里,OneVL的跑分为12.49/28.80像素,优于AR Answer和显式CoT,而且延迟远低于显式CoT的10.74 秒。
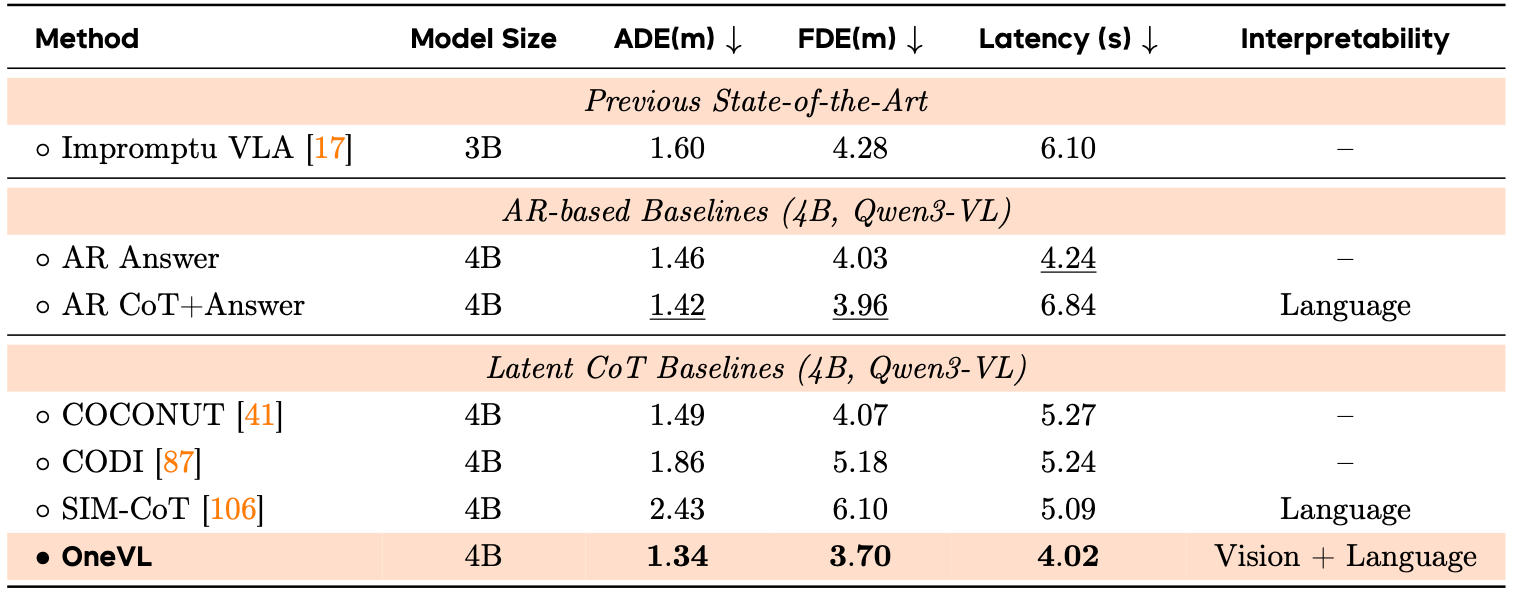
▲Impromptu性能对比
在Impromptu面对非结构化长尾场景中,OneVL的跑分为1.34/3.70米,优于AR Answer的1.46/4.03米和显式CoT的1.42/3.96米,说明整条未来轨迹更贴近真实结果。
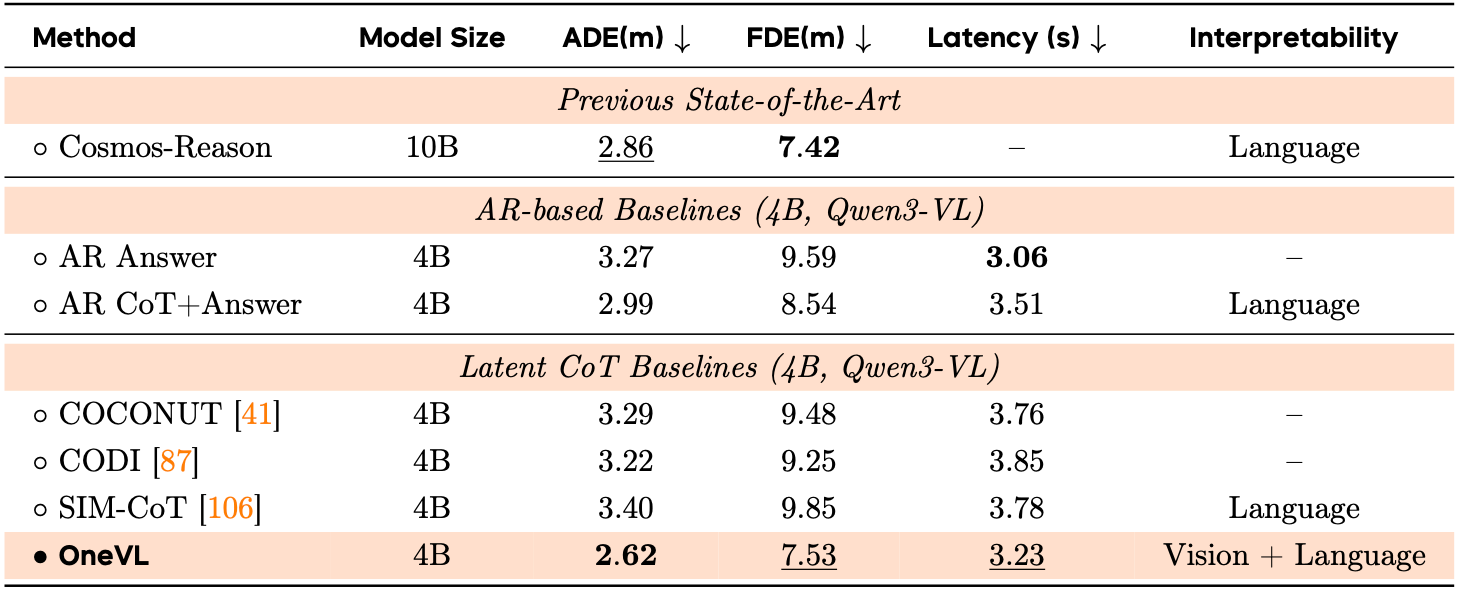
▲Alpamayo-R1性能对比
最后在Alpamayo-R1这个强调复杂因果推理的基准上,OneVL的跑分为2.62/7.53米,其中ADE优于英伟达自家Cosmos-Reason系路线的2.86 米,但FDE略逊于后者的7.42米。
这组结果说明OneVL在速度和精度之间找到了一个更好的平衡点把推理压缩到了latent token里,让模型在推理时一步激活。
与此同时,消融实验也说明了OneVL到底强在哪里。
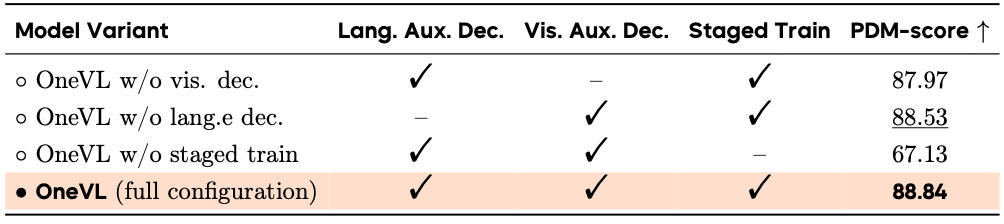
▲OneVL的消融测试结果
去掉视觉辅助解码器后,NAVSIM的跑分会从88.84降到87.97,去掉语言辅助解码器后,跑分会降到88.53。
这说明语言解释有帮助,但视觉世界模型监督贡献更大,也符合轨迹预测的任务本质:自动驾驶首先是空间和运动问题,未来画面预测比纯语言解释更直接地逼模型学习道路、车辆、障碍物的动态变化。
值得一提的事,论文最后还探索了一个更偏车端部署的版本。
这个版本在NAVSIM上的跑分是86.83,低于完整OneVL的88.84,但推理延迟只有0.24秒,约等于4.16Hz。
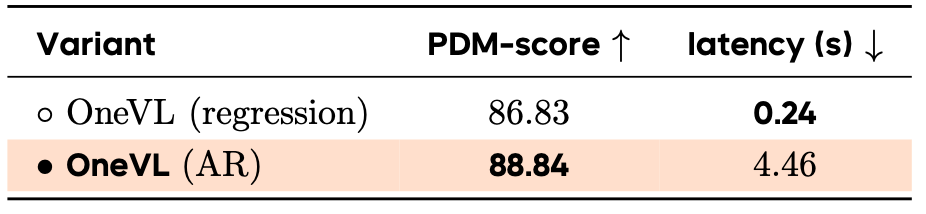
▲轻量版本在NAVSIM的跑分
这说明OneVL实际上提供了两种路线,完整版本精度更高,部署版本速度更快,但会牺牲一部分精度。
对于真实车辆部署来说,这种取舍很重要,因为车端系统不只追求最高分,还要考虑响应频率、算力预算和稳定性。
结语:小米再发新模型
总体来看,OneVL的价值不只是“又一个开源模型”,而是提出了一条更清晰的路线:训练时让模型同时学会语言解释和未来视觉预测,推理时把这些能力压缩进 latent token,一步完成规划。
这也解释了为什么它能在速度接近answer-only的情况下,精度超过显式CoT。
这个模型把思考从“逐字说出来”,变成了“压缩在潜空间里一次性完成”。
对于自动驾驶VLA模型来说,这可能是一条更接近真实部署需求的技术路线。