








2025年1月14日,第四届全球自动驾驶峰会将在北京中关村国家自主创新示范区展示交易中心-会议中心举行。全球自动驾驶峰会由智一科技打造,已经成为国内自动驾驶领域最具影响力、规模最大的产业峰会之一。
本次峰会由智一科技旗下智猩猩、车东西共同发起,以“技术新周期 产业新征程”为主题,全方位呈现自动驾驶端到端新周期里的科研成果、技术探索、产品方案创新与未来趋势。
峰会由“主会场+分会场+展区”组成,主会场将进行开幕式、端到端自动驾驶创新论坛城市NOA专题论坛,分会场将进行自动驾驶视觉语言模型技术研讨会、自动驾驶世界模型技术研讨会。其中,分会场两场技术研讨会为闭门会议,主要向持有峰会通票或贵宾票的用户开放。主会场与分会场外则设有展区。
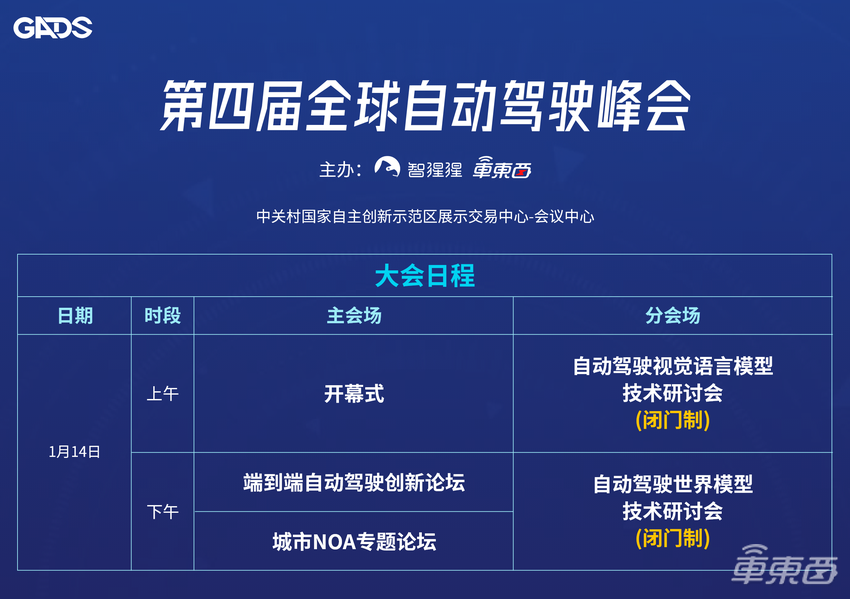
作为本次峰会的两场技术研讨会之一,自动驾驶视觉语言模型技术研讨会将在分会场的上午进行,由主题报告和圆桌Panel两个环节组成。
目前,自动驾驶视觉语言模型技术研讨会邀请到MiniDrive作者、中国科学院自动化研究所多模态人工智能系统全国重点实验室助理研究员戴星原,DriveLM一作、上海人工智能实验室青年研究员&香港大学博士生司马崇昊,Senna一作、华中科技大学Hust Vision Lab与地平线联合培养博士生蒋博,LMDrive一作、香港中文大学MMLab在读博士邵昊4位青年学者带来报告。
上海人工智能实验室青年研究员司马崇昊将以《面向端到端自动驾驶的视觉语言模型研究》为主题带来开场报告,探讨如何将基于海量网络数据训练的VLMs与端到端驾驶系统相结合,以增强其泛化能力,实现与人类用户的交互;并介绍提出的新任务Graph VQA。司马崇昊博士曾以一作/共一的身份在顶会顶刊上发表论文10篇,并参与UniAD、BEVFormer以及DriveLM等多个端到端自动驾驶项目。
端到端目前十分火热,地平线是最早一批探索和应用端到端算法的企业。华中科技大学Hust Vision Lab与地平线联合培养博士生蒋博将以《地平线在端到端/VLM/VLA的探索与思考》为主题,介绍地平线在端到端方面的最新技术探索,包括首次提出的多模态概率建模VADv2,基于扩散模型的端到端策略DiffusionDrive,以及VLM+端到端的大模型Senna。
中国科学院自动化研究所助理研究员戴星原,博士毕业于中国科学院大学。曾在各高水平期刊会议发表论文50余篇,并获得过ITSC 2022最佳学生论文奖、DTPI 2023最佳论文奖等。本次将以《构建高效轻量化的自动驾驶视觉语言模型》为主题带来报告,深入解读高效轻量化的自动驾驶视觉语言模型MiniDrive。
香港中文大学MMLab在读博士邵昊师从李鸿升教授和王晓刚教授,曾在各顶级会议上发表十余篇论文,2024年度Google Scholar引用超过500次,还曾获得2022年度CARLA端到端自动驾驶挑战赛冠军。他将在研讨会上介绍团队提出的一种新型语言驱动的自动驾驶框架,分享在基于MLLM的自动驾驶领域相关研究进展;并探讨将世界模型引入框架的尝试,构建端到端的闭环系统。主题为《基于视觉语言模型的自动驾驶新框架探索》。
一、自动驾驶视觉语言模型技术研讨会议程

二、技术研讨会报告人及报告主题介绍
上海人工智能实验室 司马崇昊

报告主题:《面向端到端自动驾驶的视觉语言模型研究》
内容概要:
我们探讨了如何将基于海量网络数据训练的视觉—语言模型(Vision-Language Models, VLMs)与端到端驾驶系统相结合,以增强其泛化能力并实现与人类用户的交互。虽然近期有研究尝试通过单轮视觉问答(Visual Question Answering, VQA)将VLMs适配于驾驶场景,但在实际驾驶中,人类驾驶员往往需要多步推理。人类在决策前,通常先定位关键目标,再评估对象之间的相互作用,最终选择具体行动。我们提出了一项名为Graph VQA的新任务,旨在通过感知、预测以及规划三大环节相互关联的问答对,来建模图结构的推理过程。我们发现,该任务可以作为模仿人类多步推理过程的有效代理任务,从而为端到端自动驾驶系统注入与人类类似的可解释、多阶段决策能力。
华中科技大学Hust Vision Lab与地平线联合培养博士生 蒋博

报告主题:《地平线在端到端/VLM/VLA的探索与思考》
内容概要:
端到端目前十分火热,地平线是最早一批探索和应用端到端算法的企业。在本次分享中,我将介绍我们在端到端方面的最新技术探索,包括首次提出多模态概率建模的VADv2,以及我们最近提出的基于扩散模型的端到端策略DiffusionDrive;另外,我还会介绍我们最近公开的VLM+端到端的大模型Senna,分享我们对于自驾VLM/VLA未来方向的一些看法和思考。
中国科学院自动化研究所多模态人工智能系统全国重点实验室助理研究员 戴星原

报告主题:《构建高效轻量化的自动驾驶视觉语言模型》
内容概要:
现有视觉语言模型在自动驾驶领域的应用受限于高计算成本和低实时性。本报告提出一种高效轻量化的自动驾驶视觉语言模型MiniDrive,通过特征工程专家混合模块和动态指令适配器,实现多视角图像高效处理和动态交互。MiniDrive在保持小参数量(83M)和低浮点运算的同时,实现了更高效的视觉语言建模与多任务处理,为构建可部署的自动驾驶视觉语言模型提供了可行的技术路线。
香港中文大学MMLab在读博士 邵昊

报告主题:《基于视觉语言模型的自动驾驶新框架探索》
内容概要:
当前自动驾驶系统在长尾事件和复杂城市场景中仍存在安全隐患,而大型语言模型(MLLM)的推理能力为突破这些瓶颈提供了可能。首先,我们介绍我们提出的一种新型语言驱动的自动驾驶框架,该框架结合多模态数据与自然语言指令,提升车辆在动态环境中的理解与交互能力。其次,我们介绍MLLM在自动驾驶领域的相关研究进展,以及其在感知、推理和决策中的应用。最后,我们探讨了将世界模型(World Model)引入框架的尝试,构建端到端的闭环系统,以进一步提高系统的安全性和鲁棒性。
三、峰会报名进入最后阶段立即抢票参会
自动驾驶视觉模型技术研讨会是第四届全球自动驾驶峰会的两场闭门制技术研讨会之一,将在分会场的上午进行。另一场闭门制技术研讨会是自动驾驶世界模型技术研讨会。研讨会主要向持有峰会通票或贵宾票的用户开放。
除了通票、贵宾票外,大会也开放免费票申请(需经主办方审核通过)。不过,持有免费票,无法参加两场闭门制技术研讨会,仅可以参加主会场(开幕式、端到端自动驾驶创新论和城市NOA专题论坛)。有需要的朋友可以申请。
敲重点!免费票不能参加自动驾驶视觉语言模型技术研讨会哦~希望到现场的朋友,可以扫描下方二维码,添加小助手“行远”进行咨询或抢票。已添加过“行远”的老朋友,给“行远”私信,发送“自动驾驶”即可。


