








导读:
12月27日,新一期地平线「你好,开发者」工具链技术专场在智猩猩顺利完结直播。专场由地平线编译器研发部负责人李建军主讲,主题为《地平线编译及编程实践》。
主要包含四个部分:
1、深度学习算法和应用的演进
李建军博士首先介绍了深度学习算法的演进,从ResNet、MobileNet、EfficientNet再到最新的Transformer,总体趋势是AI模型越来越复杂,模型结构也越来越复杂。软件开发方面,尤其在自动驾驶软件方案上,比如规划控制等,基于数据驱动的机器学习方案也在逐渐替代基于规则的方案。深度学习算法和应用的演进。
2、智能芯片架构的演进
“芯片架构的演进方式受算法和应用的牵引,是非常直观的。输入变了,肯定也会体现在芯片架构上。”
李建军博士介绍了征程历代芯片架构的迭代过程,强调了计算架构的复杂度提升会给编译器优化相应带来很大复杂性。
3、地平线编译优化实践
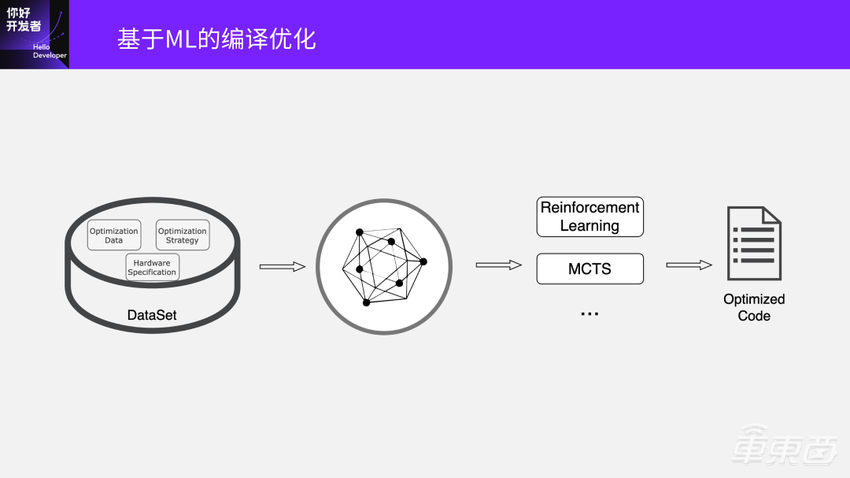
李建军博士介绍了地平线目前的第四代在研编译器架构HBDK4的结构和编译流程,重点讲解了为什么选MLIR并且对比了 MLIR和TVM。目前编译器优化现状为在编译性能和编译速度之间做权衡,针对现状李建军博士介绍了目前在探索的用RL(强化学习)的方法去提升编译效果和速度。
4、数据驱动的软硬件协同设计
最后,李建军博士分享了地平线在编译部分做的一些前沿技术探索——主要是数据驱动的软硬件协同设计。总体可描述为一个闭环:算法模型结构搜索、BPU架构搜索、RL编译优化,三者是互相依赖的过程,闭环中可以锁定任意两个来找另一个的最优解。
本文是此次专场主讲环节的实录整理。如果对直播回放以及Q&A有需求,可以点击阅读原文前去观看。
李建军:大家好,非常高兴能有机会和大家一起交流讨论。我是编译器研发部负责人李建军,今天主要是讲的是地平线在编译和编程方面的实践。
讲到编译器,大家首先会想到它输入是算法和应用,它的目标是使算法和应用在一个芯片架构上非常高效地运行。很多人认为编译器是一个架在算法应用和实际芯片中间的桥梁,编译器对于芯片能发挥的效率起到了非常关键的作用。
我会从背景出发,聊一下这些年深度学习算法应用的演进,还有智能芯片的架构,以及地平线为了应对这些变化在编译优化方面做的实践。最后讲一下我们在软件协同设计方面对前沿技术的探索。

01、深度学习算法和应用的演进
首先我们讲的是深度学习算法和应用的演进,这还是蛮有意思的一件事情,因为第一个网络我选的是ResNet。我大约是在2016年的时候来的地平线,这篇文章是2015年开始爆火,到现在谷歌的引用量已经19万多了,是非常夸张的引用量,影响力非常大。直到现在,各大芯片公司,比如NVIDIA,展示它的芯片有多高的算力的时候,基本上都会拿这个网络来看一下。
会选这个网络是因为它对AI芯片或GPU都非常友好,而且它的计算访问比特别高,计算非常规整,都是Convolution,只有一个Max pool,到比较靠后的地方才有一个Global avg-pool,中间是非常规整的Conv ReLU这种pattern。
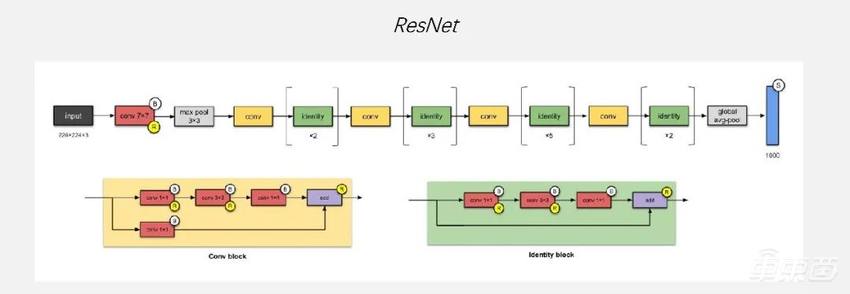
大约在2015、2016年的时候,有很多初创的芯片公司都在针对ResNet网络做优化。当时大家都会认为做AI芯片特别容易,如果是针对这个网络,确实特别容易,因为它对AI芯片的复杂度要求很低,且计算访问比也很好。
但是过了很短的一段时间大家发现,ResNet网络的计算密度太高了,当时在端侧很难找到一个非常大算力的芯片把网络跑得特别好。所以,有人提出了MobileNet,其实是在ResNet的基础上做了一些优化。
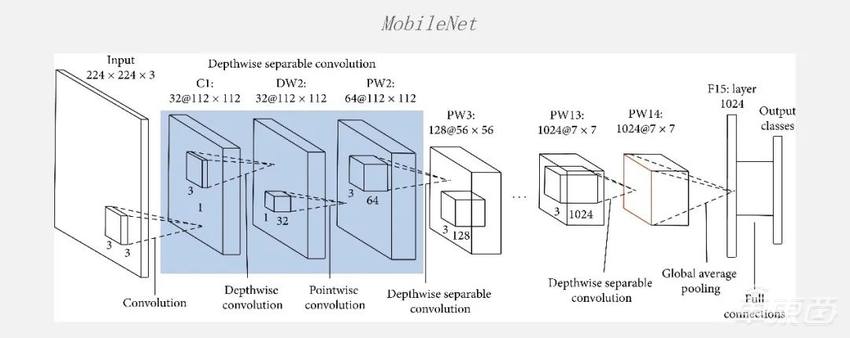
一个最基本的优化方法是提出了Depthwise Convolution,把普通的Conv拆成了Depthwise 和Pointwise,在CPU上达到了一个非常好的效果。当时那篇论文也是在CPU上,MobileNet比ResNet跑得速度快很多,但是精度基本上相当。当时大家都觉得很好,但在GPU上跑的时候大家又会发现:加速比其实没有那么高,而且在当时的一些专用的芯片上也去做了各种尝试,Depthwise Conv就会完全卡住。
再接下来就是2017年的时候Attention被提出来。从那之后很多网络都朝着这个方面去发展,后来又提出了EfficientNet。
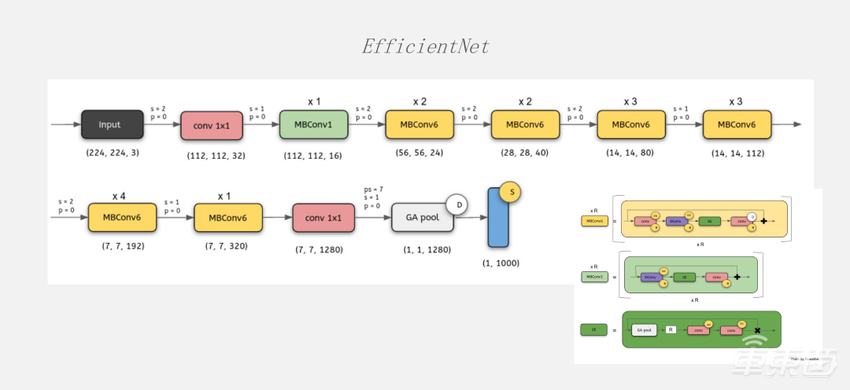
这个网络和ResNet、MobileNet框架上非常像,但内部又有很大的区别,在每个block内部的计算复杂度和算子的类型都发生了非常大的变化,在这个地方出现了很多Vector的计算。
而最近几年有Transformer一统天下的趋势。模型结构不管从算式的类型,还是从模型复杂度来说,都对AI芯片提出了非常大的挑战。
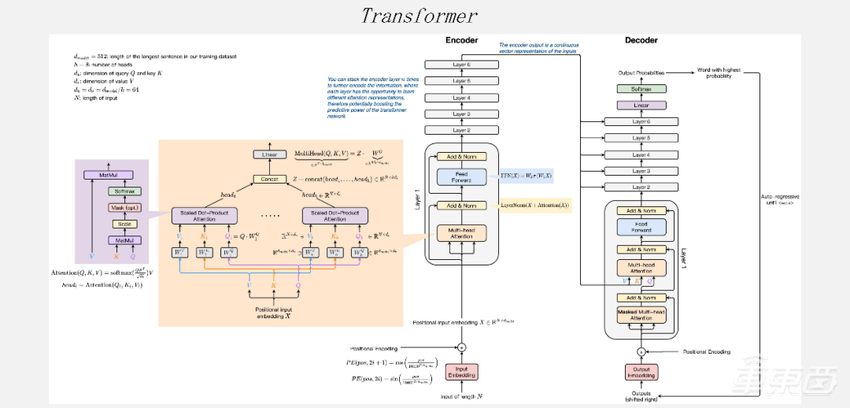
在这段时间大家发现,通过ResNet、MobileNet,GPU有一段时间比AI芯片差一些,但Transformer出来之后,GPU的竞争力又回来了很多。一个非常关键的因素是模型的复杂度,它对通用性的要求非常高。如果大家在做智能芯片时对通用性、应用性考虑的不是很好,那么它的效果在Transfomer类网络上会差很多。
整体来看深度学习算法的演进,我们会发现非常一些明显的趋势:
首先,AI模型是越来越复杂了。
从刚开始的Convolution包打天下,大家用Conv、Pooling再加几个特殊的算子,就能做一颗能效比非常好的AI芯片。到现在的Transformer,有Conv、矩阵乘、Reshape、LayerNorm、Softmax等各种复杂算子。
随着模型越来越大,GPT这种模型出来之后,Weight都是GB级别了。
模型结构也会变得越来越复杂。这里的复杂指的是在block内部,由原来的Convolution变成了一个非常复杂的图。
其次,随着模型越来越复杂,就需要一颗异构计算能力非常强的智能芯片。
什么是异构计算能力呢?就是每个部件之间都有高速的数据共享通路,而且有灵活的控制、调度并行。比如刚才提到的Transformer,它是Conv后面跟着一个Softmax、LayerNorm,再加上其他各种Vector类型的计算。如果一个Tensor Core和Vector Core中间隔得比较远,那么数据传输的时间可能会比计算时间长,现在有很多的芯片都卡在数据传输上。
再回来看Transformer模型,与其他模型相比它还有很多不同的特点。
一个最大的特点,是刚才讲到的它不止是Tensor计算。还有很多Vector计算,比如Softmax、LayerNorm、还有Elementwise操作;另外,它里面还有大量的Reshape、Transpose类似的操作。
另一个问题是计算访存比。这里面最突出的一个模型就是现在很火的GPT大语言模型,但不管对AI芯片还是对GPU都存在让人非常崩溃的计算访存比。因为如果是Server端,GPU可以通过batch的方式变得更好。但对端侧来说,跑类似的GPT模型时使用较大batch的概率不是很大。大家可以看一下各个公司发出来的数据,在一颗芯片上,尤其是端侧芯片,它的带宽的数据除以Weight的总量,和它能跑出来的FPS是差不多的,可能稍微差一点但不会差的很多。所以这个模型在所有的芯片上基本都是卡在Weight的访存上。
针对这种问题大家也尝试了大量的优化方式,比如GPGPU,将大量连续的计算融合成一个大的Kernel,这样能有效地减少带宽。最近几年的 FlashAttention就是通过手动的方式把很多算子融合成一个比较大的Kernel,在大的Kernel里面做Tiling能有效减少片外的访存。
而对NPU来说,它和GPGPU架构是有很多区别的。因为它会有一个比较大的片内SRAM,可以通过编译来控制。这里主要是一些异构计算,怎么利用SRAM这些片内的高速缓存来减少访存量呢?
不管是GPGPU还是NPU,大家都不可避免要去解决的一个问题是:Weight就是那么大,是GB级别,再大的SRAM也访存不住,最后还是会卡在Weight的访存。Server端是通过batch来解决,而NPU大家也在想各种办法更好地解决这个问题。
另外一个问题是Reshape/Transpose的引入。
因为Reshape/Transpose很多,可能会导致这个图变得很复杂,现在的模型对图优化的需求比以往要高很多,而且有时候花了很长时间会发现Reshape/Transpose有些地方是可以消除,但是它可能是一个特殊case,通过自动化的编译手段是很难完全消除。
基于以上讲的深度学习算法的演进,我们回到应用层面,讲讲智能驾驶软件开发。
这张图是当时应该是在HotChips 2017 Adapted from Jeff Dean展示的一张图片。
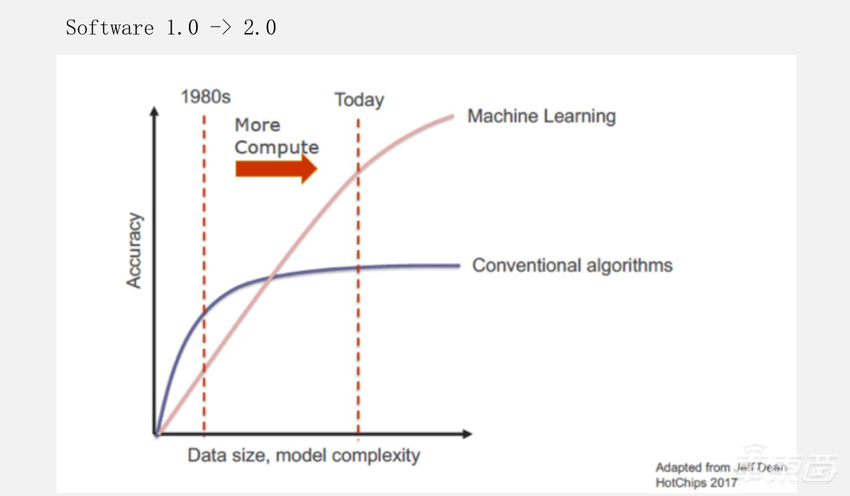
当时想表达的意思是:传统的方式基本上都是用算法来写各种应用的,而随着机器学习的不断发展,就变成了收集到大量数据之后,用机器学习的方法代替传统的算法。这里一家非常有代表性的是DeepMind公司,基本上每隔一段时间就会发一篇类似Science/Nature的文章,用大语言模型解决了哪些传统的问题。从刚开始的下棋,到解数学题,再到蛋白质分子等各种应用。证明了随着数据量的堆叠,机器学习可以解决很多原来需要通过范式的方式来解决的问题。
而对于智能驾驶软件开发来说,基本上都是朝着方向走的。这个例子是当时特斯拉AI Day展示的一张图片,主要是解决自动驾驶中的路径规划和控制问题。
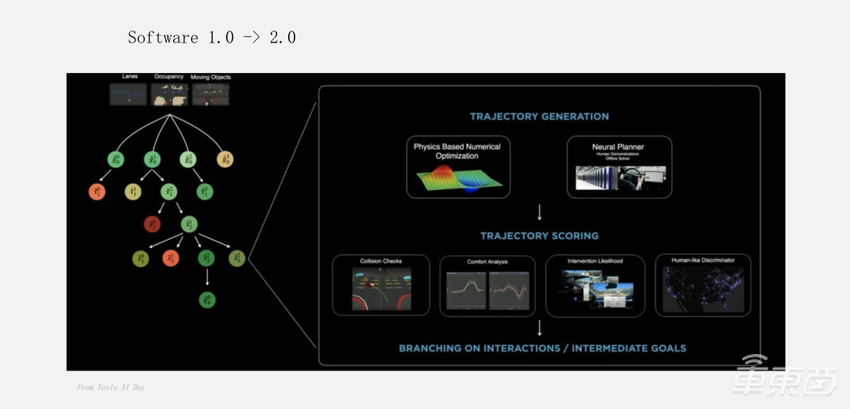
现在大家基本上也在高阶自动驾驶方向性上达成了共识:用一个神经网络去更好地预测应选哪一条路去做决策,反而比基于规则的方式更好。可能写了很多条规则,但解决不了一个普遍的问题。但如果让机器去学习,只要给它足够多的数据,就可以学出非常好的策略。这基本上是大家现在做很多复杂的软件开发所使用的一条技术路线。
软件开发是从基于规则的代码变成了数据驱动的神经网络,比如规划控制、模型的前后处理、模型的串联。但大家可以发现,这部分的算法并不是传统的静态网络,而是动静结合的,所以对异构计算的需求也变得比像Transformer这种网络更高一些。
它需要高效地执行整个应用的流程,模型是嵌在流程里的,也需要去做更多类似于模型间的LTO优化。比如一个Task同时在编译和运行时做联合优化,才能得到比较好的效果。
前面主要是讲的编译器输入,一个是算法,另一个是自动驾驶的应用。接下来我们看一下智能芯片架构是怎么演进的。
02、智能芯片架构的演进
芯片架构的演进方式受算法和应用的牵引,也是非常直观的。因为输入变了,肯定也会体现在芯片架构上。
这是地平线征程3这颗芯片的架构:
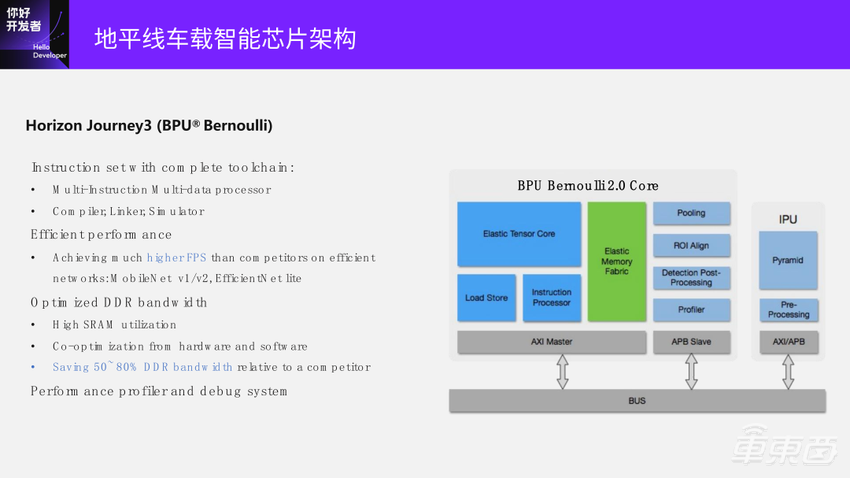
这个架构还是比较简单的,中间最大的地方是Tensor Core是MAC阵列,绿色的部分是SRAM,下面是Load Store的模块,还有一些专用的模块Pooling、ROI Align、后处理模块等。其中Pooling模块在前面几代的算法的演进过程中,是一个用的比较多的算子;还有一些专用的图像处理的IPU,Pyramid、图像的PreProcessing等。可以看到这个芯片架构是非常简单的,通过一个AXI的总线连接DDR,使DDR和SRAM之间做数据交互。这个简单的设计当时在ResNet、MobileNet、EfficientNet这些网络上达到了很好的效果。再加上编译器联合优化,DDR带宽也可以做的比较小,芯片的能效也会做得比较好。
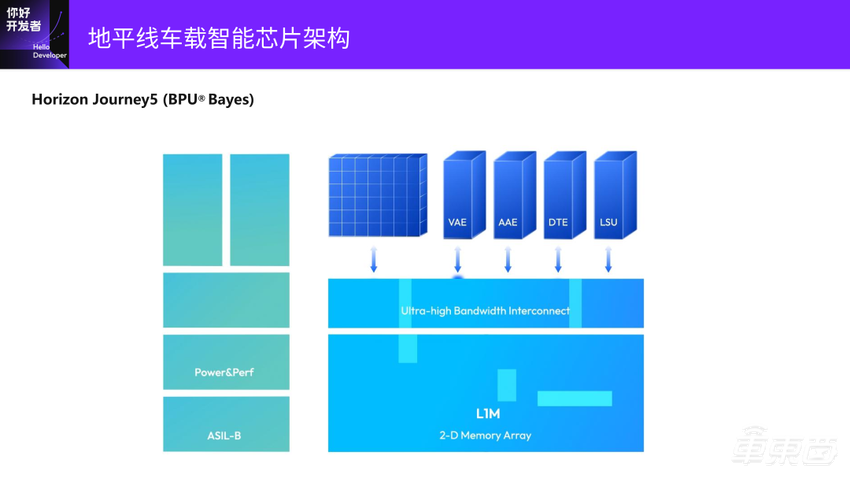
再接下来的演进就到了地平线的征程5(J5)。
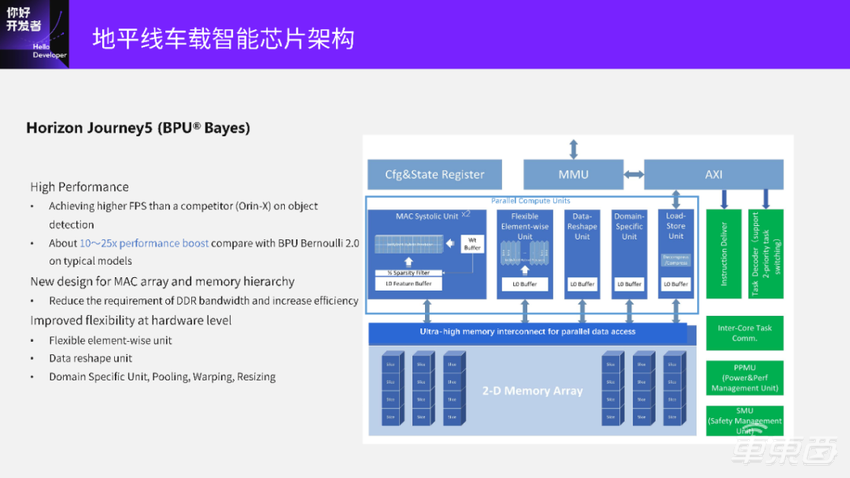
J5展现了很多算法演进以及应用软件变化的趋势。一个最大的变化是我们加了一个 Vector (Elementwise) 处理的部件,还加了一个Reshape的部件做 Data Layout&Reshape 硬件高效支持。DSU是我们的刚才说到的Pooling、PreProcessing这种模块,整个贝叶斯BPU架构的有效算力最高可以达到伯努利2.0的25倍。
下图中VAE是刚才提到的Vector部件,AAE相当于各种专用的加速核。整个数据流向算是比较清晰简单。除了Tensor Core之外,又另加了两个小的计算Vector核。
接下来是今年发布的BPU Nash智能计算架构,会用于征程6系列芯片。

这里面就比较有特点的是TAE、VAE(Vector核)、AAE,是完全从J5架构延续下来的,中间有一个带宽更大的二维组织SRAM。新加了一个浮点的处理部件VPU,还有一颗标量的核SPU,来更细粒度地控制片内的数据交互和计算调度,而且它是三级存储,在下一张图会展示。
在片上会有一个L2的SRAM,它的计算和J5是类似的,是一个紧耦合异构。所有的计算部件包括标量的核,都可以非常高效地访问片上的SRAM,并有专门的数据变换引擎,就是PPT上的DTE的部分,可以灵活地支持Transformer中各种各样的细小的Reshape/Transpose算子。浮点计算加速单元是刚才提到的VPU。
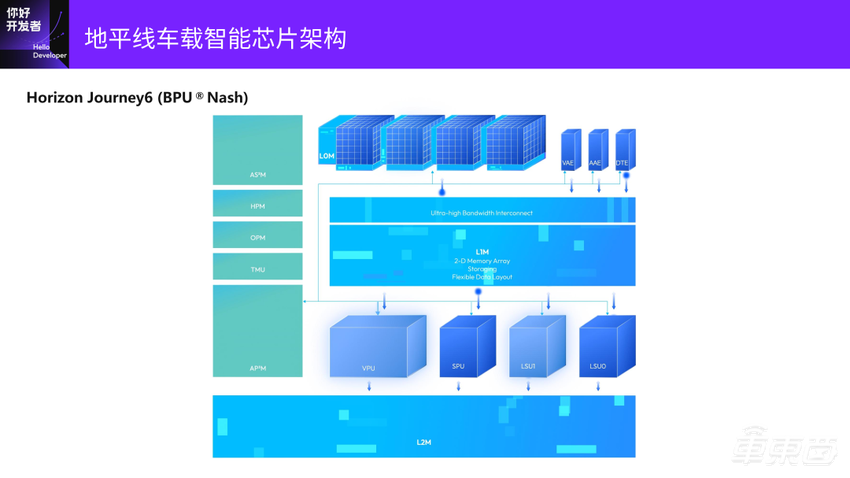
可以看到,我们在SoC上还加了一个非常大的L2的SRAM,假设SoC上有BPU核、ARM核、DSP,那就可以和它们做高速数据交互。可以看到数据交互在VPU、SPU、Scalar模块,相对于原来已经变得复杂很多。它的计算架构是变得越来越复杂,是为了更好地适应算法和应用的变化。
这样也带来了很大的好处:能够将绝大部分的模型计算在一个芯片内去完成,不需要去跟外面的ARM核去做交互;另外有一个高速共享的通路做异构调度协作。
Tensor Core有Convolution、矩阵乘等一些其他的算子。Vector Core主要是处理Elementwise,Attention结构。Scalar Core是一些控制逻辑,去做更好地调度和细粒度控制。还有一些特定的计算部件,比如特定高频激活函数的硬件加速。
但这里就会存在一个非常大的问题:整个计算架构的复杂度会给编译器优化带来很大的复杂度。如果想把它优化好,提出的挑战与原来在J2、J3上优化方式相比是一个数量级的变化。
接下来就重点讲讲地平线的编译优化实践。
03、地平线编译优化实践
重点介绍下地平线内部在研的领先编译器架构HBDK4。
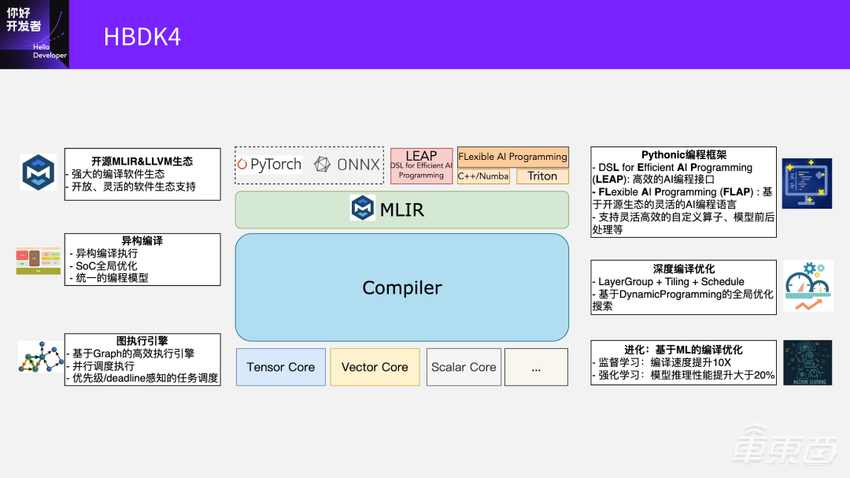
首先,这个新的架构是基于MLIR来设计编译器的流程,支持异构编译,能更好地把各种计算高效利用起来。
另外,中间有个非常高效的图执行的引擎。因为编译之后想要在芯片上高效地跑起来,就需要一个非常高效的Runtime去支撑。所以我们设计了一个基于Graph的高效执行引擎,支持各种任务调度和挑战。
大家在这里也问了一些问题,比如接下来我们的编程接口怎么样?在这一层我们会提供两层编程接口:第一个是LEAP,是一层DSL;另外一个是FLAP,是一个编程语言。通过这两层去支持灵活的自定义算子,还有模型的前后处理等各种功能。
还有一个是深度编译优化,我们现在做的编译优化从J3、J5到J6,一直是延续的。但现在也遇到了非常大的挑战,但也有了新的尝试。
接下来也会跟大家简单介绍编译优化策略的进化,是一些前沿探索。
这是我们架构的整体流程:
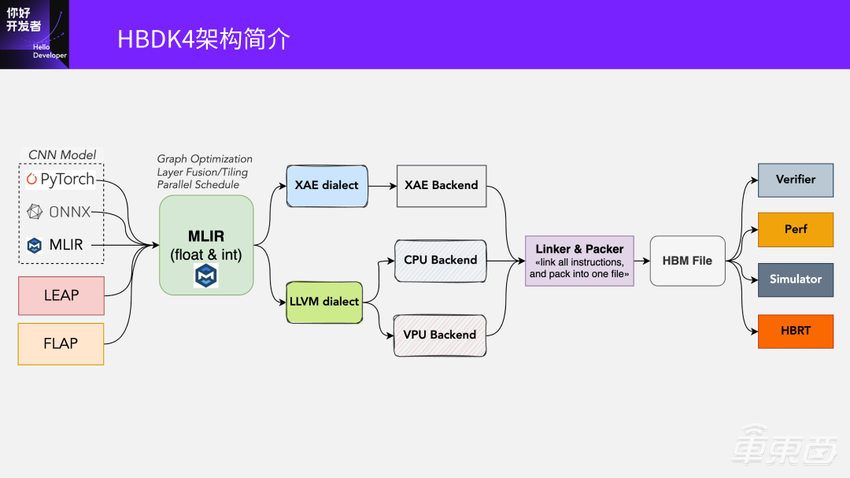
大家可以看到,我们的输入和上一页讲的类似,现在主要支持的配套框架是PyTorch、ONNX。像TensorFlow,还有更古老的Caffe,都是通过转到ONNX再进到编译器里的。另外两个输入是两个编程接口。
进来之后都会转到MLIR这一层。我们基于MLIR的基础设施构建了一个混合精度的MLIR(fioat & int)。在中间这一层中端上,我们会做大量的图优化、Layer Fusion、Tiling,还有各种调度。
在中端的优化之后,到了后端就会是分成XAE dialect和LLVM dialect。
XAE是各种硬件专用的加速核,比如Tensor Core,还有刚才说的VAE这类核。我们会把在CPU和浮点的VPU上要跑的东西落到LLVM的大类。再到CPU的后端编译完成之后,通过Linker和Packer生成一个HBM文件。这个HBM文件就是真正可以在板上可执行的文件。
编译完成之后,我们还提供了一些工具:
比如Verifier是验证编译出来程序的正确性,和原始的框架类的跑出结果是不是类似?因为中间还有一些量化问题,所以会做精度比较。
还有Perf,可以不用上板就给出大概的预估。但其实这里面有个问题:在J3这一代我们还是可以估得非常准的,唯一的变量就是DDR带宽。但到了J6这一代,随着芯片的复杂度越来越高,它的准确度会不断下降,但还是可以给大家一个差距不大的精度预估。
再一个就是模拟器。
最后是HBRT,是刚才我们说的芯片上的执行引擎。
讲到这地方,我估计大家会问为什么选MLIR?在前期收集到的问题中,也有这个问题。
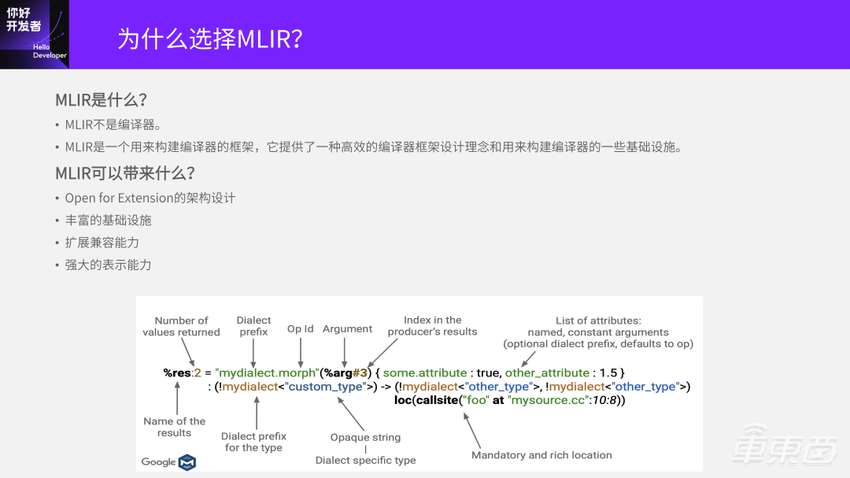
先简单说一下什么是MLIR?它不是一个编译器,是用来构建编译器的框架。它提供了一种高效的框架设计理念,还有用来构建编译器的一些基础设施。
MLIR可以带来什么?它的架构设计是非常容易扩展的,可以把AI芯片上的很多特性都通过扩展加入到MLIR表述中。它的基础设施做的也越来越完善了,兼容能力非常好,而且整个表示能力也非常强。
那为什么不选TVM?这个我觉得是对不同的公司的不同阶段,要根据需求去做取舍的问题,没有任何东西是完美的。
我们可以简单比较一下MLIR和TVM各自的特点。

MLIR是一个构建编译器的框架,不是一个编译器。而TVM是一个支持AI模型编译部署的端到端工具。端到端就是从一个浮点网络进去,可以帮你做量化、做编译,再直接到板上执行。还有TVM的Runtime到板上推理。
两者本质上并不是同一类框架,但是大家为什么一直拿它们做比较?因为在AI的大环境下,它们关注的是同一个领域,都是AI模型编译部署。
如果说,面向一个非CPU/GPU的硬件,TVM可以复用的是整个框架、前端和少量的编译passes。如果整个AI芯片的设计和GPU这类非常像,就可以用的更多。如果整个芯片的架构和GPU差距比较大,那后面很多part能直接用起来的概率不会很大。
这里面就面临一个问题:如果我们的芯片和CPU/GPU差别非常大,它的后端部分是没法复用的。而在编译器的开发中,工作量最大的就是编译器后端优化部分。
另外,从编译的框架设计来看,MLIR的设计理念是非常适合专用处理器的,而且提供了足够灵活的扩展性。MLIR现在还处于快速成长期,后面应该会有更多可以复用的基础设施,这也是我们选择MLIR的一个原因。
整个架构定了之后,刚才讲到一个编译器最大的工作就是怎么去做编译优化。

其实编译优化无非就是三步:先做融合,再去拆分,最后做并行和调度。我们会把很多不同层融合在一起,通过Tiling拆分之后,目标是将整个计算、访存完全Pipeline掩盖起来,达到非常高的Conv计算阵列利用率。
在这个过程中,地平线的做法有一些特色。
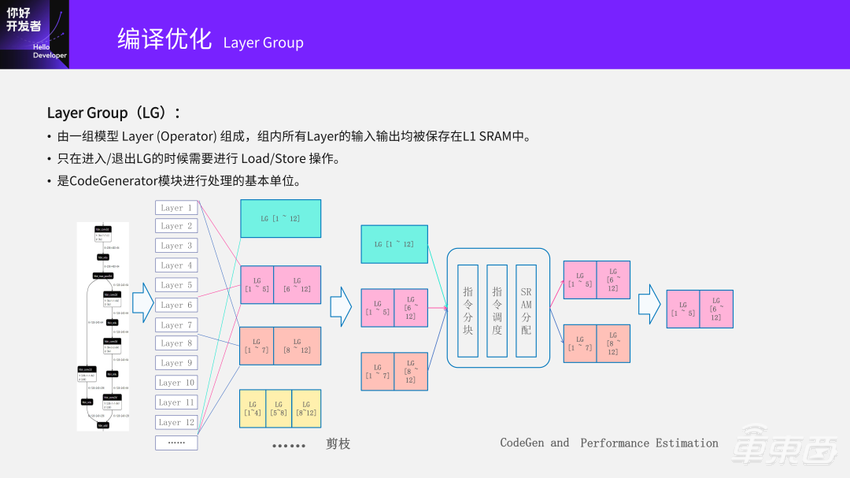
我们有一个叫Layer Group的概念。这个概念在学术界也会提到。所谓的Layer Group就是由一组模型 Layer (Operator) 组成。拿下面这个前12层这个例子来看,我可以把这些层分组,比如一个Layer Group的选择是1~12层分成一组;另外一个选择是1~5层一组,6~12一组,以此类推。
划成Layer Group之后怎么去做优化?我们默认只有进入和退出组的时候,才需要和外部的DDR做Load/Store操作去交互。把输入给Load进来,把结果Store出去。划好了组之后,后面所有的编译、Tiling、调度,都是以Layer Group为单位去操作的。
我们看下面这个例子,举了一个大约12层的例子,划组的时候就会有很多不同的选择:1~12是一组;1~5、6~12;1~7、8~12,还可以1~4、5~8、9~12后面还有省略号,这是一个排列组合问题,有很多种不同的划法。最极端的划法一个是1~12一组;另一个是1~12划成12组,每一层是一组。最原始在GPU上的做法就是每一层是一组,因为每一层算完之后到GDDR中汇在一起,再去做下一层。划完之后我们再接下来会做相当于剪枝操作,剪枝操作就是将已知的、效果不太好的剪掉。
再接下来就是以Layer Group为单位去做指令的分块(Tiling)、调度(Schedule)、SRAM分配。如果它可以正常走完这些流程,证明它是可编译的,因为在这地方有时划了组之后会编译不出来,因为中间需要缓存的Weight太大了,如果编译不了就没有意义。
通过CodeGen和Cost Model去预估生成的指令序列性能,最终选出一个计算时间最短的组合,比如选出来是1~5和6~12是最好的,优化的空间是非常大的,如果是12层就有很多不同选择。
对于n层的模型去划Layer Group就需要尝试2^(n-1) 次,还可以做剪枝操作。
每个Layer Group在CodeGen过程中,需要尝试不同的代码生成策略,比如Tiling方向、Tiling次数,还有要不要继续把中间输出的结果缓存在SRAM。
为了解决这些问题,我们现在用的一个方法是动态规划算法,用动态规划算法去搜索一个最优的Layer Group划分。但为了防止直接爆炸掉,我们会限制最大的Layer数量,比如最多搜索到50层(50层是一组是我们能承受的极限)。比如包含100层Layer模型,如果完全搜索是2^99(~6.3 e+29)次尝试。但如果用DP方法,就会把数量级降了,大约是5000次。如果再限定每个Layer Group中算子的最大数量,需要进行的尝试会更少,但没有包含Tiling、Schedule这些开销,还有Perf的预估。
我们还会去做很多启发式的剪枝优化,优化掉明显不会有收益的分支。
当我划了Layer Group之后,假设现在就是Conv2D+Pool2D+Store三个为一组,我们怎么去做Tiling,会有什么好处?很多同学都在各种论文中看到过了,基本上就是划出了更多的Tile,比如PPT中是划成了三块,释放出了很多的并行性。
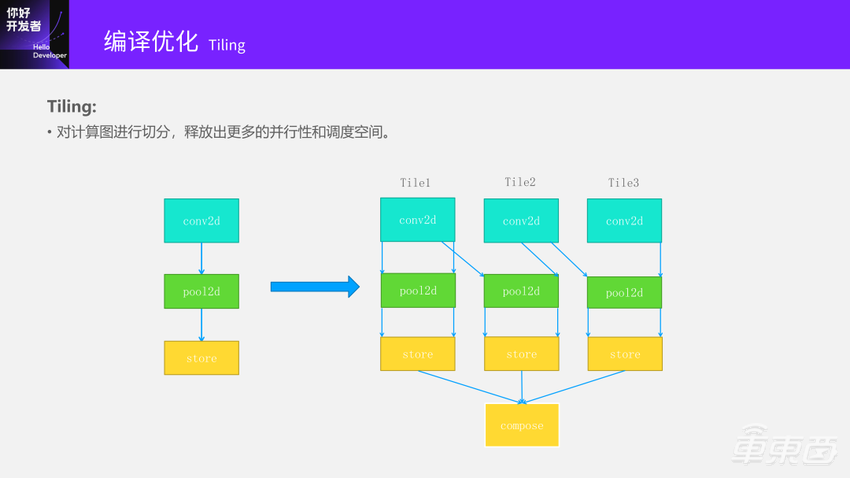
比如Tile1到最后这一段就和下一个Tile2有依赖关系。为什么会有依赖呢?因为整个Convolution的Input和Output是一个倒金字塔,有交叠问题,中间的input有交叠才能算出来两个连续的output数据。当Tile2算到一定程度之后就可以做后面的操作,而且Pooling和Store的问题就会小很多,是一个直接依赖的过程。所以它就释放出了更多并行性和调度空间。
还有一个问题是Tiling的维度。
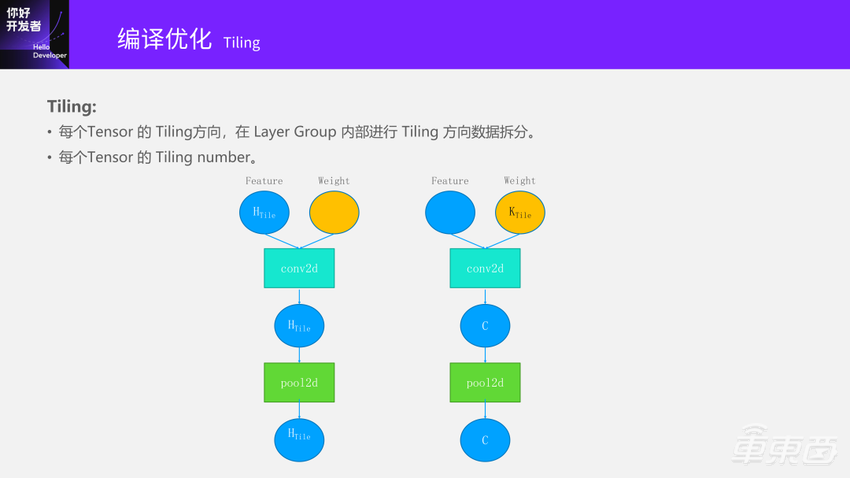
做Tiling有很多种不同的选择。只在横的方向去做Tiling,还是在竖的方向做Tiling,或者横竖都做把它分成一个块状。
另外一种选择是Tiling Weight,之后就是输出的Channel方向去做Tiling。首先的一个问题是到底在哪个维度上做Tiling?还是在很多维度上同时Tiling?假设我选择了在H方向做Tiling,到底多少块呢?到底是哪一个是最优的?
最近几年的很多论文都是要解决这个问题。比如选一个Conv,怎么知道哪个Tiling次数是最好的?从刚开始的AutoTVM,通过一些方法去搜;还有最近几年的Answer之类的论文,都是能很快速的找到最优解。在地平线的编译器中,我们也同样会遇到这个问题。
Tiling完之后,就是怎么去做调度了。

所谓的调度就是对指令序列进行重排,充分利用硬件资源提升编译性能。
同时,在调度过程中考虑SRAM资源占用情况。假设Conv2D调到这个地方之后,Input、Output需求SRAM装不下了,那没有办法只能往后等一下再执行,这是很有可能发生的。
在调度的时候要考虑还需要SRAM分配。
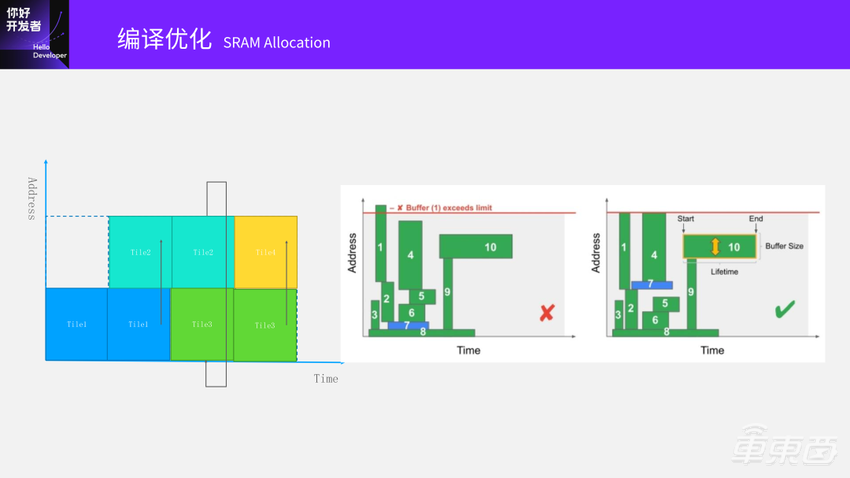
刚开始我们去做这个事情的时候,大家觉得SRAM分配应该非常容易的。如果按照等分的方式做Tiling,每一个Tile的大小是一样的。但模型变得越来越复杂之后会发现变成右边这种情况,有各种各样的大小和形状。分得不好会导致有时候能放下,有时候又放不下。因此SRAM分配算法的复杂度也提升了很多。
刚才讲的是编译优化。传统的,以及现在地平线用的,和学术上或很多公司的其实没有本质上的区别,都是基于规则的优化搜索问题。
但这里面带来的一个问题是:模型和芯片的复杂度直接影响了编译的时间。
当模型输入变大之后,去做Fusion & Tiling & Schedule的选择空间就会变大很多。模型结构复杂了,那么中间的数据对齐、调度优化也会复杂很多。而且芯片异构的复杂度、选择哪一个算子、在哪个计算核上跑,都也会带来调度空间的问题。
解决调度空间中模型性能和编译时间的问题,就像跷跷板的两端。有时候为了得到更好的模型性能,就需要更长一点的编译时间。如果有更好的算法,也可以做得更好,但这个关系基本不会发生变化。很多时候为了满足不同的需求,我们也提供了不同的优化级别,比如说O2、O3,还有Ofast。
总的来说就是在探索空间(编译性能)和编译速度之间去做权衡。
但在实际过程中会发现一个有意思的问题——编译时间长。有时候一个模型大了之后,编译时间快到一小时这个级别了,时间特别长影响开发效率。有一个解决办法是:其实有一个O2的选项,也可以达到和O3差不多的性能,但速度会快很多。但在实际使用中丝毫性能损失都不能被接受,因为到最后要上板量产的时候,需要达到极致的性能,哪怕损失5%也接受不了。
因此,还是需要想一个鱼和熊掌兼得的方式。接下来讲一讲我们在这方面做的探索与尝试。
现在智能驾驶从规则实现到了数据驱动,也得到了一些很好的效果。比如DeepMind也做了很多的尝试,从刚开始的AlphaGo是用人类的经验去训模型,得到了非常好的效果打败了人类。但后来进化到只需要告诉它的规则,通过强化学习的方式自己和自己训练,就可以得到一个比原来更好的效果,可以泛化到很多不同领域上。再到20年底的MuZero,现在又出了很多个不同升级的版本。基本上连规则都不需要告诉,只需要给一个判断,它连规则都可以学习出来。
这也给了我们很多启发:编译过程就是不断决策的一个过程。比如在哪个方面做Tiling本来就是一个决策、Tiling多少份也是决策、SRAM中放在什么地方也是一个决策,最后就变成一个离散的决策优化问题。不同的决策方式、决策序列都会影响到最终优化的效果。我们首先做了一个尝试,用的传统的DP方法和探索的方法收集到了很多的数据,作为一个数据池,设计了很多模型,包括图神经网络、蒙特卡洛搜索、强化学习的方法等来看到底能带来什么样的产出。
这是我们为了解决编译时间长的问题最先做的工作,和学术界大家做的很多东西也比较像,但解决问题的思路稍微有一点区别。
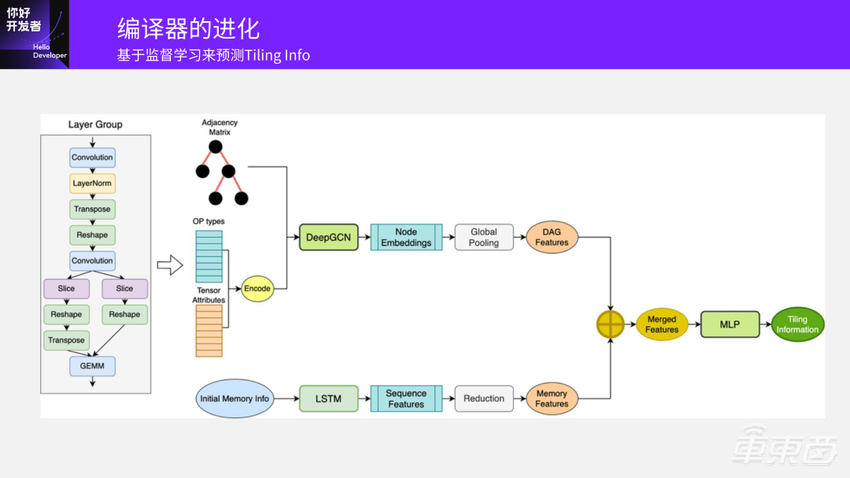
输入一个模型之后,它就是一个图,通过原始的方法就知道对于这个模型结构图,大概是什么样的分组策略,什么Tiling策略是最优的。我们先解决一个子问题,假设已经分好组了,另一个探索空间就是知道Tiling的方向和数量。我们拿已经收集到的很多数据去训练GCN网络,最后输出预测出这个子图Layer Group Tiling的维度和数量多少是最好的,基于原来的DP、搜索方法得出结果,应该不会超过已有方法的上限,因为输入数据就是这样的。
这是我们得到的一个结果:
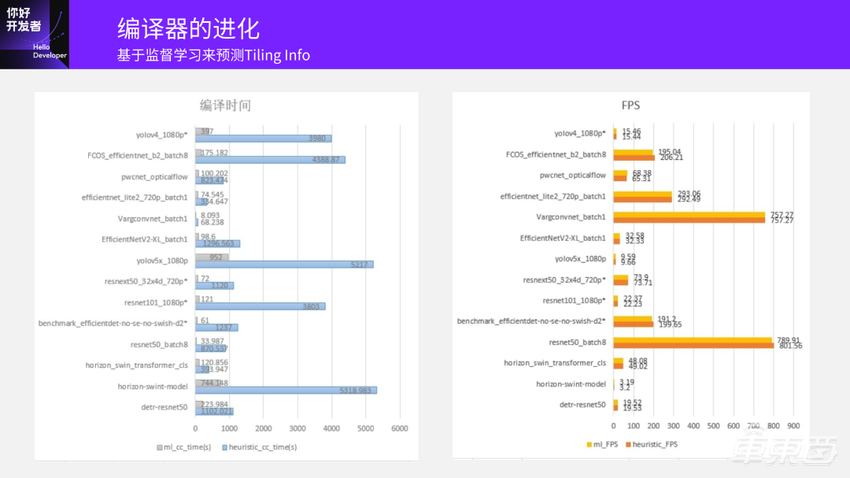
可以看到当你训练出一个网络之后,原来是通过搜索拿到一个预估的数据,耗时较多;如果用网络去推理,那么时间应该会显著降低。这里比较的是:我们用模型推理得到结果的时间,和原始编译探索过程中需要的时间。平均起来编译时间大约是原来的1/20,能达到这么高的加速。
另外一个问题是模型的精度到底怎么样?对FPS的编译性能有多大影响?
右边这个图是它的FPS,大家可以看到影响其实非常小,基本上在±1%或2%的模型性能的影响前提下,模型编译速度可以提升20倍。我们在现在发版的FP3里已经把这部分加进去了,加了一个“-om”的选项,用神经网络的方式去加速。大家如果在使用地平线的工具链也可以尝试一下,效果还不错。
但在前面我们去做基于搜索的方式比如DP的搜索,已经做了大量的剪枝。剪枝是为了能在较短的时间内(比如一个小时之内),拿到模型编译的结果,同时也丢失掉了很多优化的空间,优化的机会也就丧失掉了。
我们受到了AlphaZero的一些启发,能不能基于强化学习的方式自己去学。如果让自己去学就是把它变成一系列动作,其实也不是很麻烦。
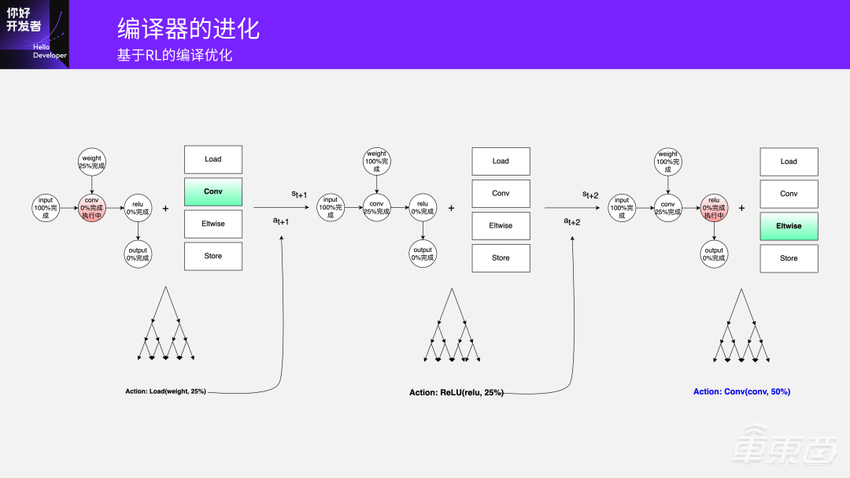
你有一个Input,假设第一层是Conv,刚开始唯一能选择的空间是Load一个Weight。当Input Load完成之后,Conv在每一步都要做一个决策,是算一部分输入?把输出store出去,把输入Load进来?还是执行其他可以选择的计算?这是每一步的Action Space可选择的计算空间,然后它自己去学。最终的一个评判标准是当结束最后一个操作的时候,所有的数据都已经处理完了。这是我们设计的一个模型。
当然,这一块我们现在还正在探索。我们也和围棋之类的做过比较,整个编译器的操作空间Action Space是比围棋的空间要大很多的。所以我们在做的过程中也在一步步把复杂度加上去。现在展示这个结果已经是把复杂度加得和真实环境非常像了,在各种SRAM的限制、Tiling的复杂度可能没有加得那么全,但已经能说明一些问题了。
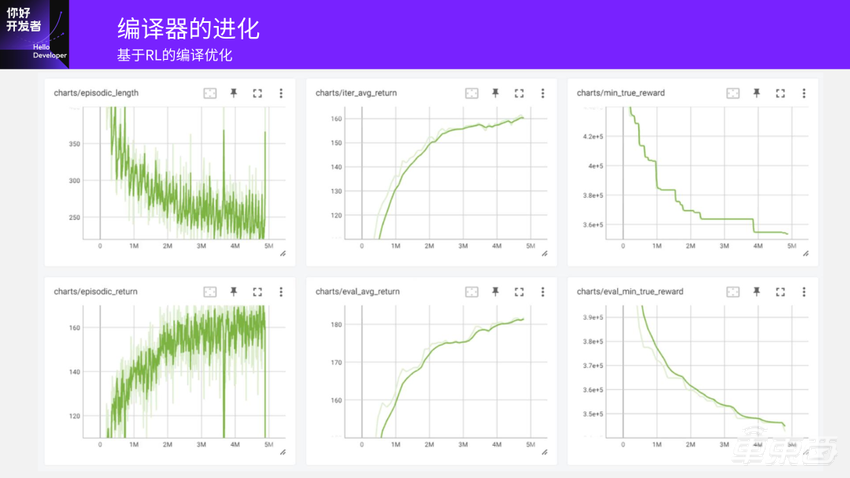
第一个图是随着训练的部署,在每一个迭代里面探索到它要做多少步才能把整个的模型都做完。
第二个图是它每个iter-avg-return,收敛速度还是蛮好的。
最后一个图是它最终训练完了之后,通过更多的尝试就可以得到非常好的性能。纵坐标是它完成整个模型需要的cycles。随着上升的指令序列走的越来越多,它已经学到了怎么做可以去达到非常好的收敛效果。
现在我们基于ResNet去做这种尝试,已经拿到了与DP的方法非常接近的效果,甚至在某些情况下,已经超出了人为设定的各种规则的指令序列。当然,我们现在还是在简单场景下尝试的,到后面还需要提升场景复杂度。不过从现在的预案探索的结果来看,我们还是有信心能达到比较好的效果。
04、编程模型
下一部分是编程模型,也是我们在这一阶段着重要去做的。
地平线在J3、J5编程接口这一方面,一直在探索更好的方式来实现更灵活地调用硬件。
在CPU/GPU上,大家用的最多是C++和CUDA,这两个生态也是非常强的。在机器学习的编程生态里,我们认为支持C++和CUDA都会有各种困难,NVIDIA支持CUDA这么多年也遇到了很多困难,证明这条路不那么好走,而且我们的芯片其实和GPGPU之类的架构上还是有比较大的差别。PyTorch 2.x系列用了Triton方式来写后端;之前还有人尝试用Numba;最近学术界也有很多新的编程模型出来,有人提出了Hidet,还有各种各样的编程方式。
我们现在正在去做的这两个编程的接口,一个是LEAP,另一个是FLAP。
1、LEAP
它就是一个DSL。DSL可以使用TensorCore、VPU、DSP(如果SoC有DSP),我们已经实现好各种指令,或比指令粒度稍大一点的功能、一些kernel,封装成一个API,让用户直接去调。用户可以基于基本的DSL进行模型串联、前后处理,因为它会非常灵活地支持一些Vector操作。
另外,我们在这一层还提供了一个C++自定义算子在框架层面的封装,统一的注册接口。这样就不需要自己再去调C++了,可以把C++直接注册到这一层接口上,模型就可以直接用。后面会有个例子给大家看一下。
2、FLAP
另一个就是FLAP。FLAP我们现在想做的是Python的编程接口,算法同学在这方面是需求的主力。后面随着需求不断增加,我们有可能支持C-like,但现在还没有提上日程。
我们现在是想做的是兼容Triton、Numba等Pythonic编程语言,已经做了初步的支持。用户可以实现灵活的自定义算子,与框架统一的Python编程界面。
看一下这个例子:
假设我们现在有一个非常简单的模型。它有Input,也有前处理,原来的前处理很多时候是用C++写的,有一些图像格式的变换等各种东西;中间是一个神经网络;之后是后处理,Output parsing解析、Layout conversion。
对于这个网络如果想去做部署,大概可以写成最右边这幅图。
我们先看前处理:假设在前处理在Python环境中可以直接使用import torch,大家对aten算子非常熟悉的,尤其是做算法的同学。可以直接用aten算子加上LEAP中提供的API或算子(它就是算子级别),直接去拼出来你想要的应用。
如果大家有自定义的一些应用,但这些在标准化算子中没有也没问题,因为你一般会用C++实现。我们提供了一个custom_op的接口,可以把你的C++算子注册进来,通过这种方式直接调用。
下面的示例是用Triton来写的,类似于后处理的过程。

如果大家对CUDA、Triton都有了解的话,就知道它是一个和CUDA比较像的并行化的东西。但它把CUDA很多比较复杂的一些东西比如memory层次等都隐藏掉了,对用户的编程门槛要低很多。很多人说它的效率在GPU上的极致情况下比CUDA会差一些,因为它是VPU,和GPU的环境不太一样,但初步来看性能还不错。
当用Triton写了之后,中间网络还不变。
你可以定义一个Pipeline,这也是用Python写的,preprocess中间调model,之后postprocess,最后return out。

这些整个都是Python环境,再加上C++已经提前把它编译成变成SO了,只需要调用它就好了。
我们HBDK4里提供了很多Python的API接口,可以准备一个输入用HBDK中的translate接口直接转成MLIR,然后去做编译,接着convert到执行的后端去做编译,就生成了一个HBM(Horizon BPU Model,HBDK编译器生成的模型文件)。

我们提供了很多接口的方式去构建前后处理。我们推荐优先用Torch Ops,因为大家对这块最熟悉。如果Torch Ops没有的话,可以LEAP(DSL)。若这两种都没有达到你的需求,可以用Triton自定义算子。你认为Triton写起来很复杂,那也可以用C++。
等到芯片发布之后,也欢迎大家去做尝试,给我们更多反馈。因为我们也在快速的迭代中。
05、前沿技术探索
最后讲一下地平线在编译这部分做的一些前沿技术探索,主要是数据驱动的软硬件协同设计。
地平线的硬件编译器和芯片走得非常近,是非常典型的“软硬协同”的工作模式。在芯片的架构中,我们会参与的非常早。在讨论芯片架构的过程中我们编译器团队就会参与进去,和芯片团队一起讨论指令级别的架构是什么样;构建接下来的性能评估的工具,去评估在新的架构下,什么样的模型能跑出怎样的性能。我们也会在不断迭代的过程中给芯片团队很多反馈,比如需要芯片实现某个功能,使整个编译器更加高效,芯片团队也会跟我们一起讨论是不是有其他的方式。
编译器和BPU耦合得非常紧,在芯片架构做的过程中和芯片回来之后,还有一个问题就是算法。一些比较前沿的需求也会同时导入进来,等芯片架构定了之后也会反过来影响算法。
这就是前面讲的,我们现在正在做的一些基于ML的编译优化的探索。
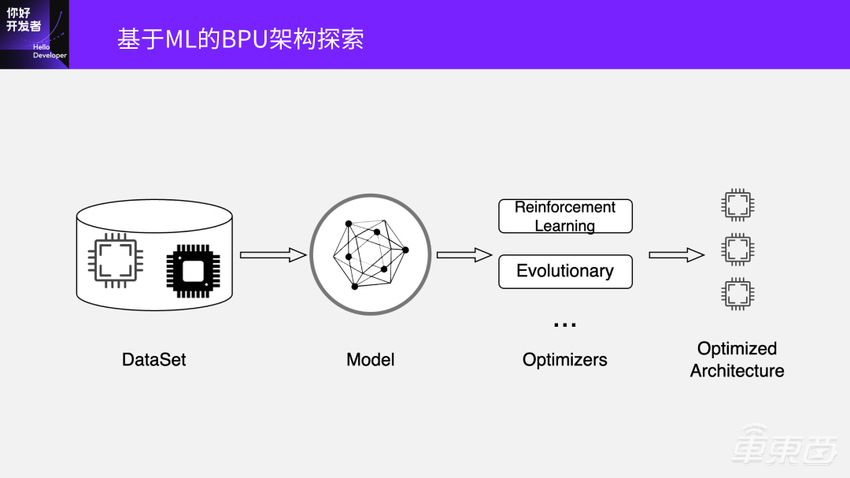
另外,刚才讲的是BPU架构。BPU还是有很大的探索空间,比如刚才讲的SRAM要设多大、Vector算力要做多少、Tensor的配比是多少、中间的带宽需要多高等各种不同的选择。到最后也变成了选择决策的问题,和编译这个事情也非常像。所以我们也开始尝试做这个方面,能不能收集很多的数据,可以通过模型告诉我们接近最优的BPU架构配比是什么。当整个编译器和芯片基本定了之后,通过NAS在一个特定芯片上搜索出最优的模型结构。
总的来说就是一个闭环:算法模型结构搜索、BPU架构搜索、RL编译优化,三者都是互相依赖的过程。通过算法、编译器、架构设计三者相结合,在软硬结合极致优化的同时,经数据驱动实现自动化验证,持续寻找BPU架构最优解,驱动智能进化“加速度”。
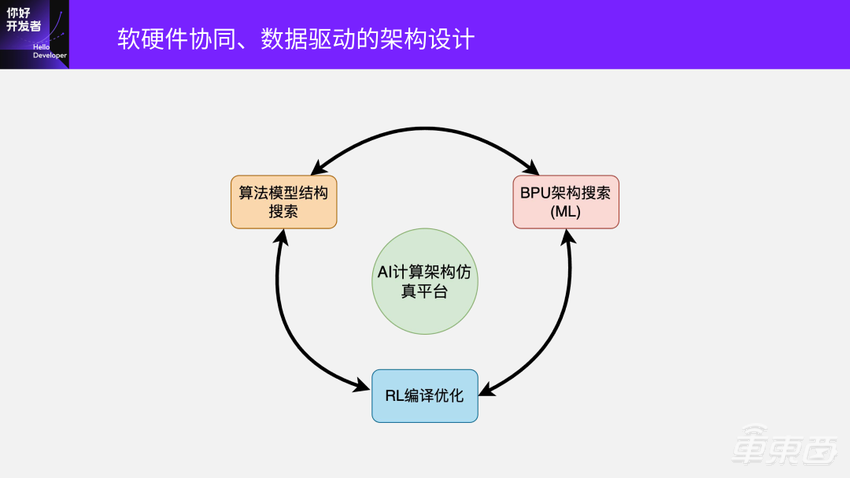
比如你要做算法结构的搜索,就需要快速编译出一个结果,然后在BPU上尝试它的性能怎么样。它对编译的速度、时间,还有编译优化的效果,都提出了非常高的要求。在这个闭环中你是可以锁定任意两个来找另外一个的最优解。为此,我们也搭建了一个计算架构的仿真平台做这方面的预研探索,极大提升智能计算架构BPU的进化迭代速度。
今天我讲的就是这些,谢谢大家!

