导读:
11月22日,新一期地平线「你好,开发者」工具链技术专场在智猩猩顺利完结直播。专场由地平线工具链量化训练工具研发负责人屈树谦主讲,主题为《地平线量化训练工具的设计与精度调优经验》。
本文是此次专场主讲环节的实录整理。如果对直播回放以及Q&A有需求,可以点击阅读原文前去观看。
屈树谦:大家好,我是来自地平线深度学习平台的屈树谦,主要是负责地平线工具链的量化训练工具。今天我们要讨论的Topic是《地平线量化训练工具的设计与精度调优经验。
我大概从这几个角度进行今天的讲解:
1.量化训练技术简介
2.量化训练工具面临的挑战
3.地平线量化工具设计和精度调优经验
4.未来探索方向
一、量化训练技术简介
大家都知道在芯片或端侧部署上,整数计算肯定比浮点计算快很多。这是一个简单的图例。
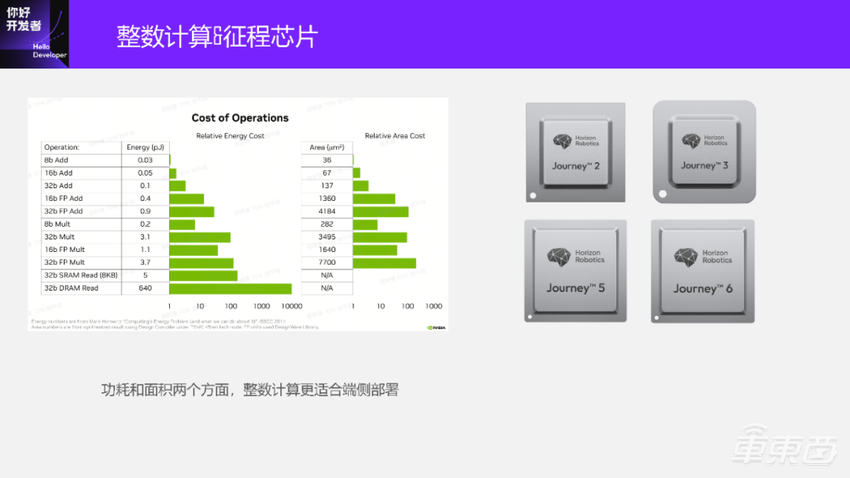
从图上大家也可以看到,比如8b Add和相同的层,其实就是数量级的差异。因此从功耗和面积的角度来看,整数计算其实更适合做端侧的部署。我们征程系列芯片从征程2、征程3、征程5,到最近推出的征程6,都支持INT8或INT16计算。我们的工具就是将浮点模型部署到我们的芯片上。
二、量化训练工具面临的挑战
大家都知道,智驾场景存在一些量化问题:
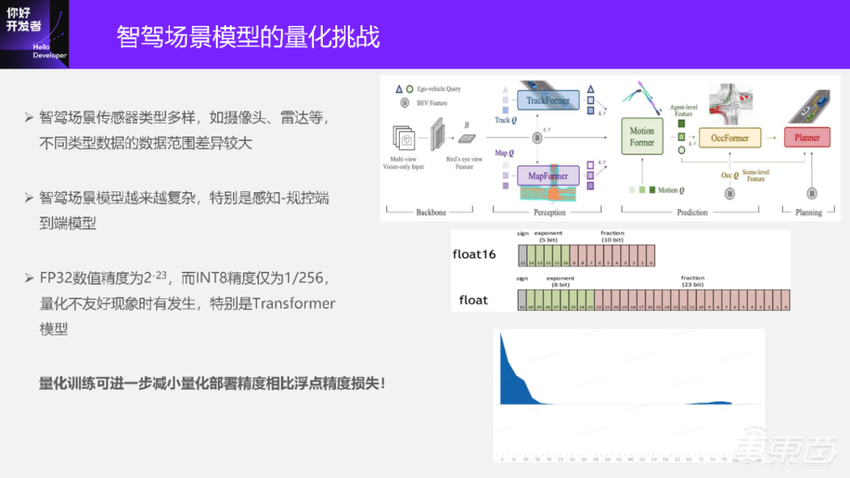
1、智驾场景传感器类型、数量都比较多,比如摄像头、雷达等,不同类型数据数据范围差异比较大。以图像为例,大家都明白是INT(0-255);而雷达有很多位置信息,甚至有速度信息,所以它的数值范围很大,这些对于量化都是挑战比较大的。今天我也看到了一些同学的问题,比如输入层是不是可以用更低bit的量化?我们当前来看,其实还是比较难的。
2、智驾场景模型会越来越复杂,特别是现在大家都追求做端到端模型。端到端从感知到规控,它整个链路很长,每个阶段的模型结构都是有gap的,所以对量化的挑战也会越来越大。在我们公司内部之前也出现过做一些端到端模型的时候,做量化碰到很多问题。
3、FP32的数值精度是2⁻²³,对于INT8来说,只有1/256,就是256个数,所以量化不友好的现象是时有发生的。大家传统上认为都是正态的,所以量化起来很容易。但实际情况并不是这样的,特别是一些Transformer模型量化不太友好。
量化训练可以进一步减少量化部署精度相比浮点精度的损失。
我对量化训练的基础稍微介绍一下,可能今天大部分同学都比较了解,但有些同学会不太熟。
量化就是从浮点到定点的映射过程,这里的公式是一个均匀的、带着zero-point的非对称量化。我们地平线当前的量化训练工具主要还是对称的量化,zero-point是0。
反量化就是反向的过程。以 Conv为例,从输入到输出,比如INT、weight都是浮点。如果是量化的过程,它的真实计算过程就变成了前面两个是有量化节点的,在量化的时候两个输入是INT8,但是输出是INT32。所以Conv是INT8的计算。
牵扯到量化训练,量化训练是一个先做量化,再做反量化的过程,就是一个伪量化的节点。这个节点在量化训练的过程中是比较重要的,它相当于在浮点训练过程中,模拟在端侧部署时候的量化过程。它的输出也是FLOAT,这个FLOAT可以认为是一个量化、反量化之后的FLOAT,跟前面的 FLOAT是不一样的。
三、地平线量化工具设计和精度调优经验

接下来重点讲讲地平线当前的量化策略。
1、 基于已有浮点模型的finetune,无需用户重新训练。
当然这是有好有坏的,这也是在社区里大家最通用的一种方式:把浮点模型训好了,然后做一次finetune。它的成本比较低,目前的认知是在浮点的1/10以下。这里面也会有一些问题,在智驾场景的量产过程中,浮点模型本身就在不停地finetune,然后再加入QAT finetune,从理论上来讲可能会存在一些问题,但我们目前还没有碰到。
另外一条路,我们也可以让用户直接基于量化的模型,就是刚才Fake-quant模型,直接做从0开始的量化训练。这个在我们公司的一些场景模型上是有适用的,它对于模型迭代来说可能更稳一点。
2、梯度计算也是业界比较通用的一种方式,就是STE。
因为量化的函数是阶梯的,是求不了导的。所以业界一般常用的方式就是透传,直接把输出的量化梯度透传出去。唯一的区别就是两头是饱和还是不饱和,这个地方要不要透传。
3、Scale更新的策略,大家特别常用的是基于统计的方式,一般不会直接用Min、Max。比如Moving averavge的一种方式,就是根据一些当前batch和之前batch的数据做的统计。
还有一种就是基于学习的方式。Scale本身也是被学习的,它也可以用求梯度的方式来做,例如LSQ。这个地平线的策略里面是支持的,还支持一种基于真实数据范围设置固定Scale的方式。
这种方式看着不那么高大上,但在很多场景都适用。对于一些数值范围,比如QAT或者Calibration塞的一些数据,不一定能够cover到一些真实的数值范围,所以这时候需要根据真实的数值范围算一个固定Scale,按浮点的Min、Max,除以INT8,比如刚才说的-128~127的Min、Max。
4、还支持浮点模型FP16&FP32的部署。征程5上采用的是异构方式,一部分是在CPU上算的,征程6上会直接支持。
我们大概从去年下半年开始就在探索一种方式:Calibration+QAT。
最早的时候,我们并没有采用这样的方式来做QAT量化训练方案。大家可能觉得QAT已经很稳了,随便搞一下精度就会上来。其实不尽然,特别是Transformer模型出现之后,大家才发现了很多量化问题,可能有时候直接塞QAT都不一定能搞定。所以我们的策略就是先做Calibration,再进行QAT。这种方式的好处是精度更有保证。在有些直接QAT上不去的case,通过这种方式是可以上去的。
我们当前大概1/3,甚至更多的参考模型是不需要QAT就可以直接满足精度的,按场景来看,大概是分类和分割模型偏多一点。当有了Calibration的Scale做基础来进行QAT时,可以让QAT的step数更少,可以更快地达到精度目标,所以整体的量化成本会更低。其实我们的用户都挺关注QAT或整套方案会带来多大的成本,除了人力的成本,还有机器的成本,比如我花了一周训了一个模型,如果QAT再花个几天,可能就接受不了了。所以这种策略可以更快达到最终部署的精度,可能之前需要花一天,现在半天就搞定。
鉴于刚才的好处,我们的Calibration策略也在逐步完善,在业界比较常用的策略,包括kl、percentile、MSE、max、AdaRound等,我们都有支持。
最近也支持了自动搜索的混合校准策略,为每一层选择最优的校准策略。这其实也是来自于客户的需求,不想每个阶段策略都配一遍,这对人力消耗的成本会比较大;另一个是用户在使用的时候,不太懂应该选哪个,因为在某些case下面很难知道哪个是最好的。所以我们有一个自动搜索策略,当然自动搜索会比较耗机器资源,相当于用资源换一些人力,对大家会更友好一点。
下面列出来的是主要是一些CNN模型的精度。
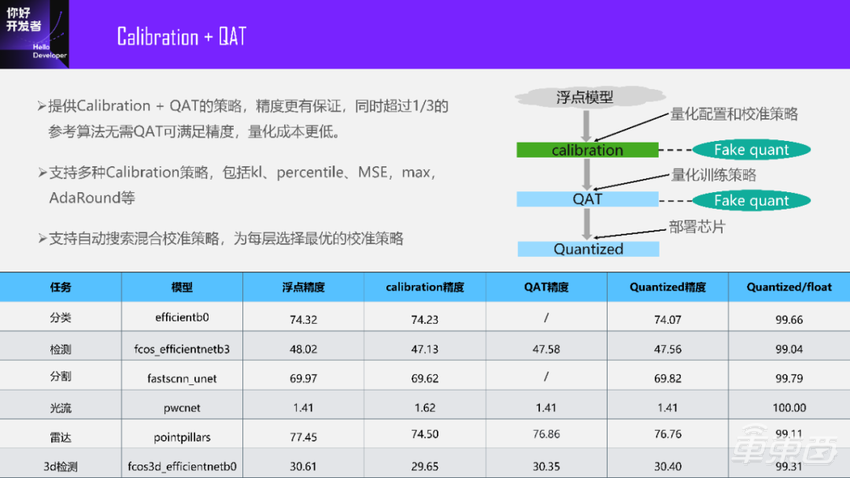
从这里面看到的比如分类、分割的模型,我们直接做Calibration就可以达到了。下面这几个模型是需要做QAT的。
再说一下我们针对Transformer的量化做的一些工作。
在早期我们探索Transformer的时候,让我们很头疼。此前我们接触的CNN模型会比较多,因为当时的Transformer方案在面向真实场景的时候还不是很成熟。但目前来看,大家在做一些比如智驾场景的融合,会用一些Transformer Attention的方案,之前其实不会,所以一开始大家也尝试了很多东西。目前我们针对这些复杂算子Layernorm、Softmax以及Gridsample,但Gridsample不能完全算是这里面的,提供了更友好的精度方案。用户可以不用感知,可以直接调社区的算子。我们会把它转到QAT的model上,内部主要是混合INT8和INT16,采用INT16解决一些精度问题,可以降低Transformer模型的量化难度。这些算子里面,比如GELU这种算子,我们没有感知到它有太大问题。
针对一些常用Attention结构,比如MultiScaleDeformableAttention,提供了精度和部署性能优化。
我大概选了几个模型,大家能看到一些分类、检测、车道线等各个场景的模型。
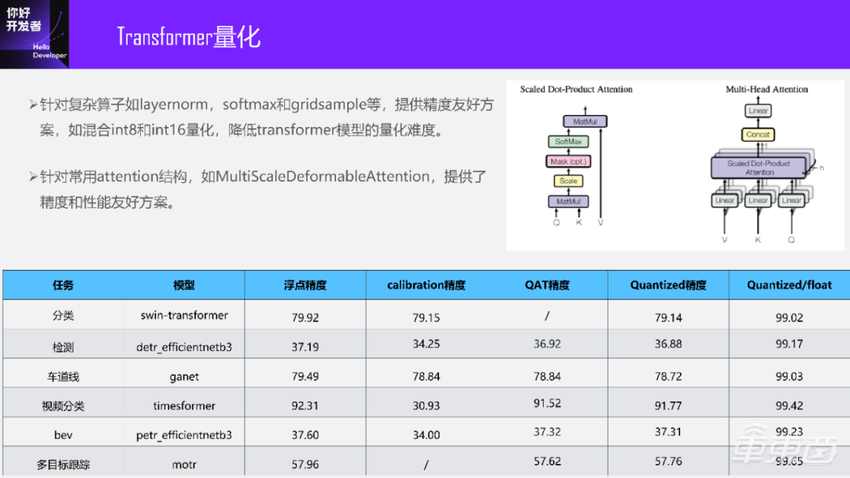
这里面的模型最终达到的精度看起来都是ok的。目前从QAT的角度来看,我们是可以解决Transformer的量化问题,不止INT8,还引入了INT16。
刚才我聊的是偏量化训练策略这部分的工作会多一点,而PyTorch量化训练接口如何选择?也是一个很头疼的问题。如果想要尝试PyTorch量化的工具要怎么做?
社区可能也提供了一些方案,但社区的接口永远都是Prototype、Beta,在很早期的阶段持续了很久。
量化训练问题本质上就是在一个合适的位置上插入伪量化节点,可能还有一些节点替换的问题,但关键的问题是插入伪量化节点。同时,还要保持训练特性不变,不能插完之后,得到了Graph,但量化的使用体验和原来的浮点使用体验不一样。这张图是2022年底到2023年初的状态,PyTorch的 capture graph方式有很多。
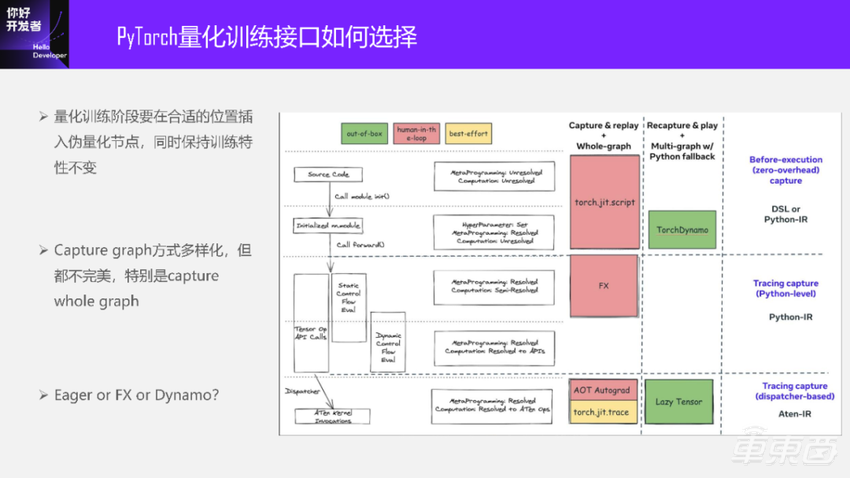
Capture方式其实是很多的,从Script到Trace,再到FX、Dynamo,不同的level上有不同的方案。我们更关注要得到一张全图,如果没有全图,有时候做点事情还是挺难的。所以我们应该选择什么样的方案?一种是没有Graph的Eager,还是用FX或Dynamo。对于Dynamo,前一段刚发布了 2.1 Dynamo export 方案。这些方案其实都不是很完美,每个方案都有自己的局限性,都会给算法同学带来一些没那么友好的东西,不能一把全都搞定。跟我们早期用的比如MXNet或者TF一样,直接把Graph的node都定义好了。这时候框架层面做起来就很简单,但可能对用户不太友好。
地平线现在支持的是Eager Mode和FX Mode两种接口。

Eager Mode的方式整体的方案上是没有图的。用户在真正做QAT的时候,他的体验是和做浮点一样的,可以做单步的调试。但因为没有图,所以在做算子融合的时候需要用户手动操作,比如融合Conv、BN和relu算子之后,量化更友好,部署也会更友好。这些是偏图优化的操作。
在Eager Mode上,部分算子需要用户手动替换,比如像加、减、乘、除。在浮点的阶段,我们可以随便调用这些算子,但是在QAT上是不一样的,如果想要add做量化,那就意味着要插一些量化节点进去。量化节点就是刚才我们看到的 Scale、zero-point等 。它们是有状态的参数,要变成一个torch model。将function替换为module需要用户手动替换,所以这个方案可能会存在的问题是它的友好性。但是在配好了qconfig、prepare之后,还是ok的。
FX Mode就没有这样的困扰,因为它有Graph,我们可以在 Graph上做一些我们想做的工作。但FX Mode有一些语法上的问题。这种方式采用proxy,而非真实Tensor,有非真实Tensor来做symbolic trace,symbolic trace会和Python语法会存在一些兼容性的问题。
整体来说,这是我们目前的方案。我们也在努力帮助用户提升量化接口的应用性。我相信后面会在这两个版本的基础上,再做一些更友好的版本出来。比如基于torch 2.1的export方式trace fx-graph。
接下来是硬件相关的优化。

1、目前的QAT还是与硬件绑定的,没有完全与硬件脱离。所以,它的目标更加贴近硬件的模拟量化,可以进一步降低从QAT模型到Quantized模型的损失。直观地说,如果你用的都是浮点,那么可能没有这个问题。但如果是在部署的时候也是定点的,还是会存在这些问题。毕竟前面是模拟的量化,后面是真实的定点,所以会有一些精度的gap。大家在刚才的那个表格里面也能看到,我们当前的Quantized相对QAT是掉的比较少的。
2、在保证精度的同时,尽量做到多算子进行量化,充分发挥硬件潜力。在之前的PPT我也说了,INT计算还是比较省的。
3、提供一些特殊场景的硬件高效算子。这些算子是在我们的硬件上做了专门地优化,把它们嵌入到工具里面,用户可以按需使用。
4、支持Quantized模型的仿真。基于GPU 和 X86的高性能仿真,我们今年也优化了几个版本。
5、支持稀疏化训练(2:4)。(2:4)稀疏可能是当前一种公认的对硬件比较友好的稀疏化策略,硬件实现成本比较低,精度损失也是ok的。我没有在这里列精度的情况。稀疏化训练+量化整个全流程下来,相对之前精度损失大概2%之内,这是我们当前的一些实验结论。它本身的流程是基于浮点模型的, 浮点模型进来之后,先做稀疏化,再做量化,再到部署。
前面讲到了我们在很多场景的复杂模型量化训练的经验。我们内部也碰到了一些复杂模型,而且我认为这个模型会越来越复杂,至少目前没有看到这个事情变得越来简单,我们也有了一些经验:
第一个是某些场景模型的输入,如雷达数据。对于雷达来说,不同channel的数字范围差异会比较大,不太适合量化。所以,我们建议用户做归一化之后,再到网络里面做量化,这时候的量化损失会比较小。
第二个是视觉Transformer,比如BEVFormer,有很多参考点、位置相关的信息;再比如Gridsample的Grid计算也是和位置相关的,不管是相对位置还是其他的,因为量化敏感度比较高,都需要更高的精度。我们建议是INT16量化,或根据真实的数据范围设置固定Scale。
这个我刚才也提到了,就是为什么要做这样的工作?其实有时候为了做量化,这些工作是必要的。我们看到实验场景下QAT都是跑多遍数据集,但大家在真实场景上做模型的时候,都是按step算的,而不是epoch。step的话,我能在 QAT跑1000个step,所以能跑多少数据是不确定的。大家按照某个标准来选数据的时候,不一定能很合理地选择,所以这个case很可能是需要设置固定Scale的,后面我们也可以让用户设置一些浮点进来。
第三个是检测等模型,比如网络输出和算法指标关系比较大,我们建议设置高精度输出,或者默认都设置高精度。
这是从其他地方找过来的一张图。

比如大家学到的Scale、Min、Max,都是基于统计的方式来得到的,有一些异常点会被去掉。但有些点是挺重要的,比如刚才说的位置的点,如果无脑地做饱和是有问题的。
这就是我们对复杂模型的调优经验。当前我们公司内部和很多的公司外的量产客户都用了这套工具。
下面是丰富的精度调优工具。这边我列了里面很多的工具,包括一些模型结构的检查工具、排查共享op、算子融合、量化配置等。
共享op对于浮点用户来说,可能很多时候没什么概念。特别是PyTorch里面,比如像一些检测的头里面,可能某一个Conv得过好几遍,但是共享op对量化不一定友好。共享op的问题在于:本来是一个Per-Tensor 的 Scale,但共享了之后就相当于是Multi-Tensor的Scale,一个Scale管着多个Tensor。除非每次跑多个分支的时候,它的数值范围分布差异很小,这个时候是没有问题的;一旦有一些差异的时候,精度就有问题了。所以我们是不推荐大家在QAT阶段使用共享op的,当然有一些工具可以check出来。
下面是一些提供相似度、统计量的工具,方便大家查找量化敏感层。
还有支持单步调试的工具。单步调试和浮点的使用体验是一致的,这就像PyTorch最大的优势就是Python程序,大家都一样是Python程序,没有变成别的东西。
最后一个是支持部署一致性对齐工具。
调试需要付出一定的代价,不是免费的。至少我们还没有一个特别优秀的metric一把搞定所有的case。所以需要通过多指标来共同分析,哪些地方可能会带来量化问题。
我们内部也在持续地探索,怎么把这个事情做得更好?比如会尝试让大家找bad case,如果大家直接跑这些工具,可能有时候反映不出来。但可能找到一个bad case之后就ok了。这就和debug程序一样,我们尝试通过类似的策略来提升,后面也会持续完善。
这是当前的精度调优的一个流程图,我就不具体展开了。
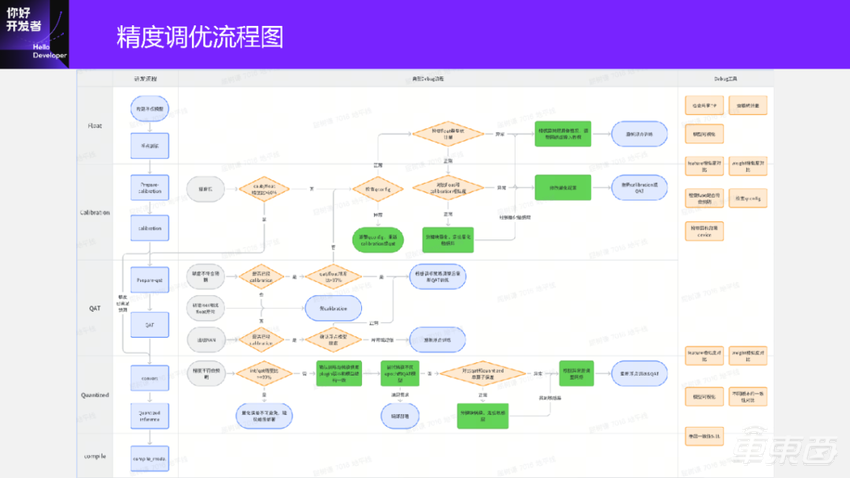
在浮点、Calibration、QAT、Quantized各个阶段都可能会有一些量化问题。比如Calibration,我没有期望Calibration一把就能达到损失1%以内,很多时候是达不到的,这时候需要大家调到QAT上,网络结构,Calibration策略或量化配置都可能有问题。
QAT转换到Quantized模型的问题在于精度可能会掉,掉的问题有多种,我举一个比较典型的例子:某一个非线性的激活,比如 EXP,看着就很怪异,我们量化的时候会把它变成查表,因为查表在硬件里是最好的,算的速度也特别快。但在这时候你的表怎么找、怎么定表区间,这些都是问题。我们内部是会自动来查找这些东西,但确实出现过1~2个case,我们查到的表区间也是不太合理的,这时候需要做微调。
再推荐新一期地平线「你好,开发者」工具链技术专场:12月6日,地平线模型转换和量化工具负责人何道远将主讲《地平线模型转换与训练后量化部署》,报名通道开放中,欢迎扫码参加~

四、未来探索方向
最后是我们未来的探索方向。

还是会持续探索复杂场景模型的量化部署,因为现在的模型确实越来越复杂。
数据的量化部署、量化调优、精度调优的流程也要持续完善。之前PPT出现过的有一些模型,这些模型确实要花不少时间debug。如果是一个完全不懂量化算法的人,不一定能把量化完全搞定。某一些case的量化不友好,可能是因为绑定了输入、输出的物理含义。作为一个做量化工具的人,有时候不一定能够感知到这些物理含义。所以大家都要互相懂。做量化的同学要懂一些算法,做算法同学要懂一些量化。目前来看,我们认为这是不可避免的,只是懂的程度的问题。我们也在持续完善,希望让大家尽量少懂一点,能一把或者几把就搞定了。
提升算法迭代的效率。毕竟大家都在抢时间、冲量产,大家已经花了很久来调浮点模型的精度了,不想再花这么长时间来做量化。我们也希望把这套流程做的更完善一些,可以提升迭代效率。
探索更低bit的混合量化。可能不只是更低bit,包括INT8、INT16,FP16甚至更低。因为硬件上会支持各种各样的数据类型,这些数据类型在什么情况下才是硬件性能最优的?对于QAT来说,确实有很多空间可以探索。QAT对于量化的问题,它的容忍度会更高一点,所以它更有可能会得到部署精度更优的模型。
探索LLM大模型的量化部署。我今天讲的内容还是量化训练更多一些,大模型的问题可能在于没办法做完整的finetune,把所有的数据再来一遍,这个可能是大家不能接受的。当前大家是只是跑一点数据,类似刚才说的复杂模型,大家都是跑step,而不是跑epoch。如果有的跑step数少,有的跑step数多,带来的精度就不一样。
这些就是我们要探索的一些后续的工作。
我今天要讲的内容就是这么多,谢谢大家。