导读:
8月24日,最新一期地平线「你好,开发者」自动驾驶技术专场在智东西公开课顺利完结直播。
专场由地平线感知算法工程师朱红梅博士主讲,主题为《基于征程5芯片的BEV感知方案与部署实践》。本文是此次专场主讲环节的实录整理。如果对直播回放以及Q&A有需求,可以点击阅读原文前去观看。
各位智东西公开课的朋友们,大家晚上好,我是来自地平线的感知算法工程师朱红梅,今天很荣幸跟大家分享《基于征程5芯片的BEV感知方案与部署实践》。我将从五个方面去展开介绍。

01
BEV感知框架总体介绍
随着2021年征程5芯片的发布,我们基于征程5芯片设计了 BEV的感知原型方案,输入的是车载多视角的图像序列或者多模信号,在网络内部进行时空维度的中融合,使得神经网络能够原生输出鸟瞰视角下的动静态感知、预测结果。
下面是一个框架图。
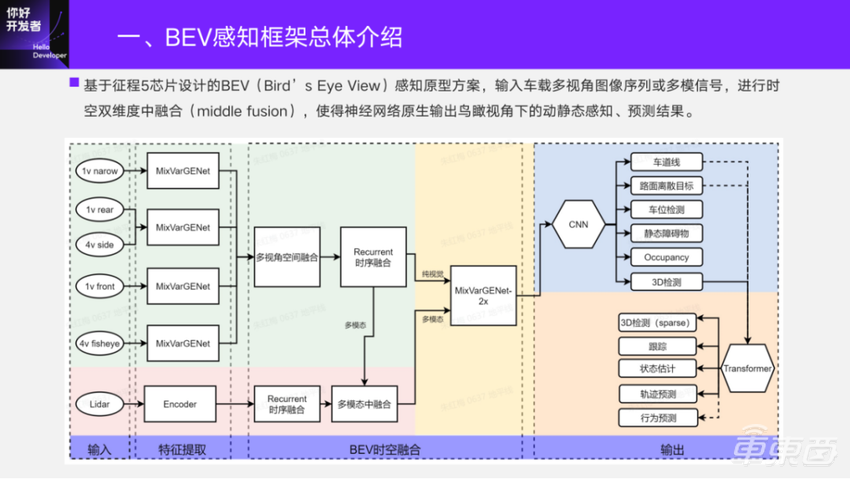
绿底部分表示纯视觉的信号处理,输入的是各摄像头的图像,经过第一阶段的模型提取图像特征,通过视角转换做 BEV视角下的多视角空间融合;再对BEV的特征进行时序融合,进而送入第二阶段做BEV上的特征提取;最后,输入到head部分做感知要素的输出。如果系统里有Lidar,也会接入 Lidar点云。前期会做栅格化的编码处理,也会做时序融合,最后和视觉的BEV特征做中融合,同样也是送入到二阶段去做BEV上感知要素的输出。
蓝底的部分是已经参与过多轮的闭环迭代。关注地平线的同学应该知道在今年4月份的上海车展上,这部分内容已经支持了闭环的实车demo展示。在最近半年,我们对其中“动态障碍物检测”在感知要素功能上进行了扩充,基于它接了Transformer的 head,去做动态障碍物的Track id、速度估计、轨迹预测。虚线部分是目前我们正在研发的,也是想充分利用BEV上的动静态感知结果做动静态感知需要交互的要素输出,比如行为预测。
这里的纯视觉方案主要有两种模式。一种是面向双征程5芯片的行泊一体11v融合方案;另一种是面向单征程芯片的方案,其中行车7v融合、泊车5v融合。今天的分享主要针对视觉方案里的时空融合部分,感知要素的解析,还有关于动态的,特别是动态感知预测端到端的方案与部署的介绍。
02
时空融合模块与芯片部署
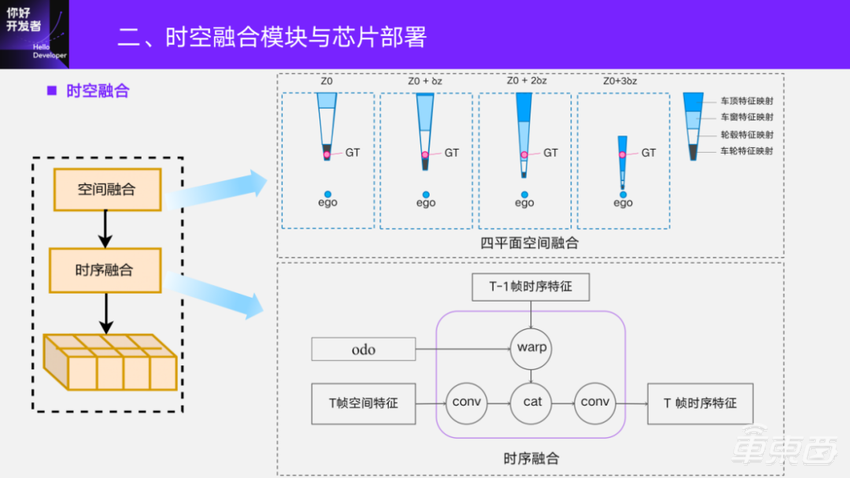
首先介绍一下目前板端采用的是四平面的空间融合方法。它是以自车坐标系的xy平面作为基础平面,在此基础上增加了三个高度平面,希望获取更多不同高度的场景图像信息。时序融合这一块比较简单,我们会缓存上一时刻时序融合后的特征,利用帧间的自车运动将历史帧对齐到当前帧,并与当前帧的空间融合特征进行融合,再去卷积送入到后面的网络结构做感知输出。
那么为什么我们用这样的方案呢?
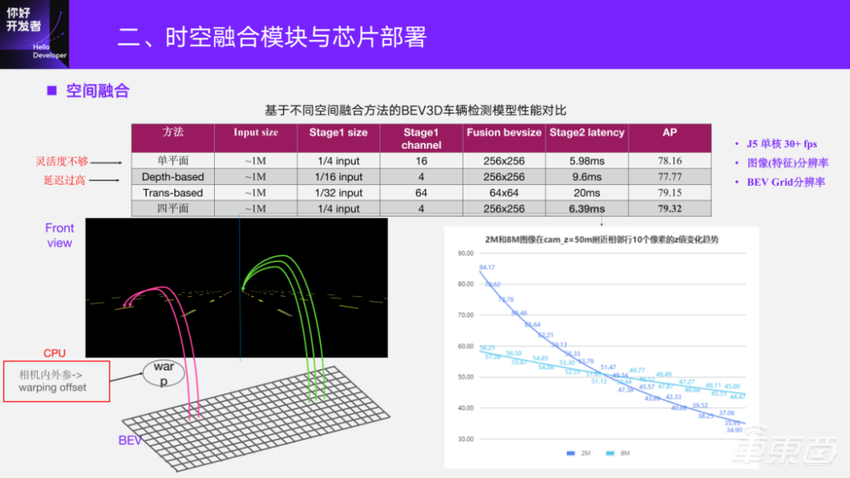
在研发前期,我们也对比了不同的空间融合方法,前期为了快速打通流程,采用了最简单的基于单平面IPM的方法,打通了整个框架的感知。之后去摸底了征程5上做基于深度的融合以及基于Transformer的融合方案。考核维度是在征程5上的延迟,假设前提条件是能够在征程5单核上独立跑这个模型到30fps以上,去设计相应的网络参数。
这里影响BEV的感知性能有两个关键参数,一个是一阶段的图像feature分辨率,另一个是BEV上的融合分辨率。对于BEV上的融合分辨率是比较直接的,分辨率越高,对于一些小目标的感知以及点元素的感知更有优势。图像分辨率决定了二阶段输入的信息量。
这里有一个车道线模拟图,每一段车道线的物理尺寸是一样的。由于是透视投影,在图像中越远的车道线,它的成像像素会相对越少。BEV索引图像特征,一般是一个逆向实现的过程,而BEV上一般是等分辨率去设计的,比如说常用0.6、0.4米Grid分辨率。当通过 BEV的坐标去索引场景中比较远的目标时,图像里的像素对应的物理分辨率就已经比 BEV上分辨率要低了,这时候BEV上就会出现特征重复,也就是常见的拉伸现象。反映到感知上,比如检测框可能会出现目标分裂成一串的现象,所以一阶段的 feature分辨率也是非常重要的。
我们抓取了中间这一列像素,去模拟2M图像和8M图像在50米处相邻两行像素的z值变化对比。可以看到,低分辨率的图像在相邻两行像素对应的物理范围变化已经达到2米多了。对于高分辨率的图像,它相邻的两像素只有0.6米左右。所以反过来看融合方案时,不仅要考虑单个任务是否满足一定的精度要求,还要考虑最后部署的时候,因为是多任务不同感知要素输出,所以希望一阶段的特征和BEV融合的分辨率能够更高一些。
从这个角度来看,目前基于Transformer的结构能够满足征程5单核30+FPS的一阶段分辨率和二阶段融合分辨率都比较低,并且在这个条件下延迟过高。而基于深度的融合方法一阶段相对单平面来说较低。另外没有采用它的一个原因是基于深度的部署针对征程5做了一些特定的改进,达到一个9.6ms的二阶段延迟。在原型方案验证的阶段,对于车上搭载不同数目的摄像头的灵活度是不够的,所以在这个阶段我们采用了平面映射融合方法。前期用单平面,而实际去做闭环验证的时候发现单平面对相机参数的泛化性、鲁棒性确实不够,且又比较敏感。所以我们在进一步的研发过程中去改进,通过多种测试、验证,最终采用四平面的融合方法,它在性能和延迟上面都能达到比较好的平衡。
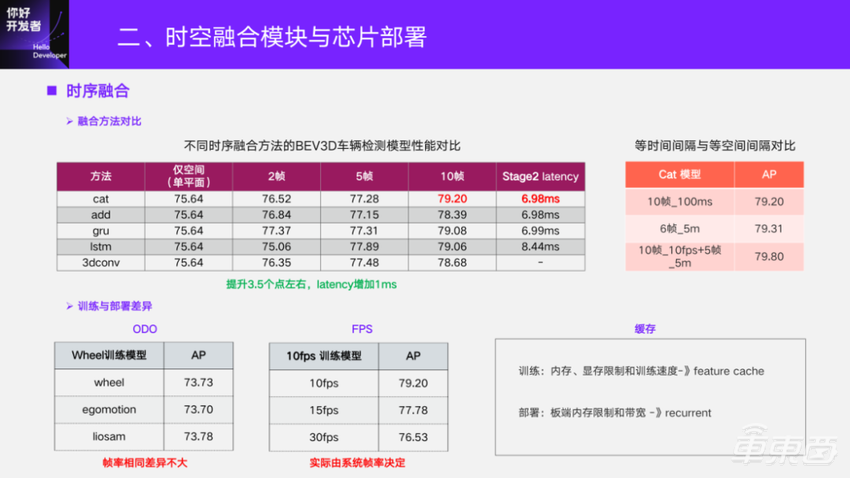
对于时序融合,研发前期同样也会对比不同的时序融合方法,基本的做法都是先将历史的BEV特征对齐到当前帧,采用不同的融合方法去做时序融合。这里也是对比了融合不同帧数,用当时积累的实验数据做了10帧的验证。在10帧情况下,相对于仅空间有3.5个点的提升,对于latency,因为部署的时候是 recurrent模式,所以仅仅增加了1ms。
同样我们也对比了获取历史帧的两种方法。一种是等时间间隔的去截取历史信息,另一种是等空间间隔。等时间间隔是用系统的时间戳去索引,读取相应的帧。等空间间隔就是随着自车的运动算平移的距离,然后去取帧。最终我们发现,6帧的等空间间隔和10帧的等时间间隔性能是差不多的,两者也可以做结合,但多一些融合帧提升并不是很大。所以为了部署简单,我们目前采用等时间间隔的时序融合方法。
时序融合在训练和部署的时候有几个点可能存在差异,一个是对齐相邻两帧的时候用的Odometry,为了使训练的模型性能和实车部署的一致性,遵守的一个原则是模型输入尽量和板端信号一致。我们用轮速计的Odometry去做模型训练,在不同的方法获取的Odometry上做测试。发现如果和训练时候的帧间间隔是一致的,那么这个因素影响不是很大。另外,比如100ms间隔取得了历史帧,用10fps训练数据训练的模型,在10fps、15fps、30fps上去做测试。得到的结论是,如果部署和训练的时候差异比较大,指标差距会更大一些。实际的系统帧率是受系统实时的负载影响,可能无论怎么设置训练时候的帧间间隔,都不是完全对齐的。一般周视感知能够在15fps左右,基本上能满足功能需求,在1.5个点的范围也是能接受的。这部分也可以通过一些数据增强的手段,使得时序训练数据的分布更丰富,缓解这样的问题。
另外一个是时序在训练的时候,如果没有特定的优化,时序数据随着帧数的增加,可能出现内存、显存的一些OOM(Out of Memorry)问题,从而导致训练速度过慢。训练的方法是采用feature cache策略去缓解或者避免这样的问题出现。但是在板端部署时考虑到板端的内存限制和加载回来的带宽,最终板上采用最精简的一种策略recurrent模式。
03
静态与Occupancy感知要素解析
静态感知的一个重要的组成就是真值,BEV上的真值是怎么来的呢?
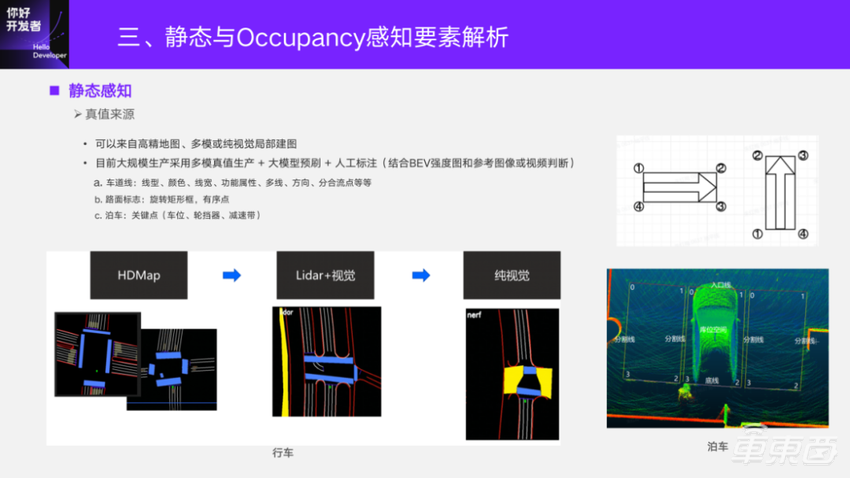
从最开始研发到现在,用到过三种静态真值。最开始用过高精地图,现在大规模使用的是基于多模的真值生产链路,目前也有纯视觉的局部建图结果参与到了训练当中。对于建图质量的好坏,是由我们公司专门的4D-Label团队负责开发。在地平线「你好,开发者」自动驾驶技术专场上一讲,地平线4D标注技术负责人隋伟博士也跟大家分享了《面向BEV感知的4D标注方案》,如果感兴趣可以去回顾一下。
对于算法而言,算法同学要更多地参与到标注规则的制定。即使真值是大模型刷的,大模型也需要真值,所以标注规则需要感知算法的同学深入参与,特别是实际测试场景是非常复杂的。标注规则的一个参考条件是建图得到的Lidar点云底图,是一个BEV上的强度图,再通过参考图像或者视频去判断,才能去标注。比如车道线,要标注颜色、一些功能属性和一些下游功能所必须的且从Lidar底图上无法得到的,都需要结合图像去做。对于路面标志一般都是去标旋转框,对需要有明确方向指向的,需要标有序的点列。泊车的要素基本上是以关键点的标注方式去标车位、轮档器、减速带等。
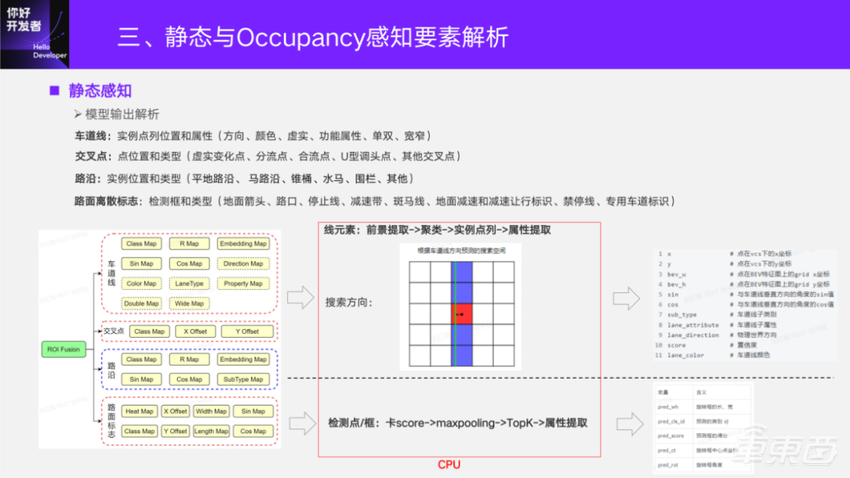
模型的输出跟标注是对应的。标注的信息会做一定的预处理,生成模型的真值。真值做监督输出,才能满足下游的功能需求。车道线输出的是实例点列位置和属性;交叉点是点位置和类型;路沿也是实例位置和类型;路面离散标志是检测框和类型。这些静态感知要素是非常丰富的。对于模型方案,有一个前景提取的分类学习,一个精确位置的回归学习,车道线还有一个实例特征的学习。整体来说静态感知方案比较常规,在解析的时候,像车道线这种线元素会通过Class Map的score去提取前景,再通过 Embedding的相似度去做聚类得到这个点列,反向地去属性特征上去索引这些点相应的特征。
对于车道线而言,在实际软件解析的时候,要考虑软件上面的延迟,按照预设通过垂直点去大致地估计车道线的方向,沿着这个方向做一维搜索,缩减车道线的后处理时间。现在我们的方案最新优化,对这部分处理不到3ms。路面标识、交叉点的检测点或者框这一类的解析是CenterNet那一套:卡score→maxpolling→TopK→属性提取→输出。
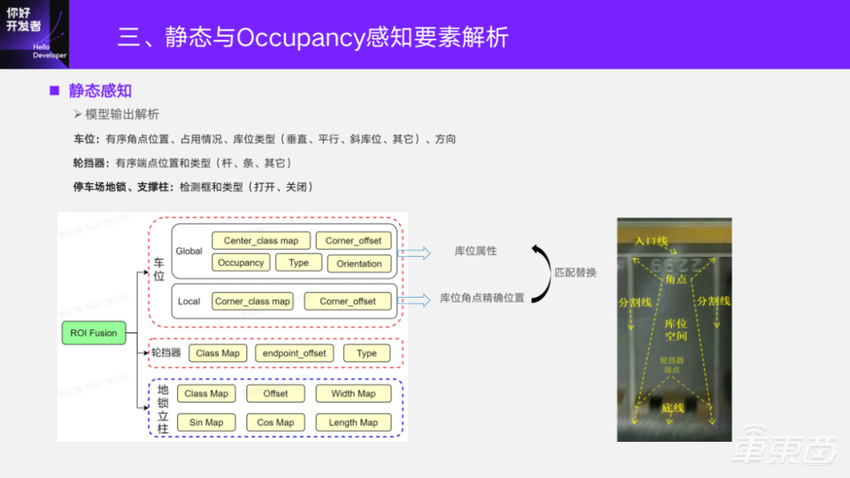
对于泊车要素,车位会输出有序的角点位置、占用情况、车位的类型方向;轮挡器是有序的端点位置、类型;停车场下的地锁、立柱都是以检测框输出,和前面的点和线框的解析思路是一样的。这里的车位是有两个小head,其中一个是为了获取车位的整体属性,比如它的占用情况,车位类型是平行库位还是垂直库位。还有一个Local的head,是为了精确地估计库位的角点,因为对库位这种角点的精度要求非常高。在得到了比较精确的之后,再和 global下面得到的粗糙的角点位置去算点的匹配。因为这个点是有序的,卡一个距离的阈值即可,匹配完之后做角点坐标的替换,就可以得到一个库位的精确的角点坐标。

这是我们性能上的表现。地平线的2D感知方案之前也是打磨了比较久,对BEV的感知来说,相当于有一个很好的参考baseline。
车道线和路面标志相比于2D的方案,在测距上,比如车道线在不同距离段,路面标志的箭头、停止线,都有一个比较大的提升。对于车位,地平线也有一个前融合方案,送入网络前先把4路鱼眼图像先做IPM融合,得到覆盖自车周围360°的IPM图像,再融入网络做车位的输出。现在BEV就是前面框架介绍的,在模型内部对feature 做融合。目前在这三类库位上面同样都是有比较大的提升。
看一下这个视频,这是一个高速的车道线的可视化展示,有一条宽虚线,接下来出匝道。这里是一个分流点、虚实变化点,箭头代表方向。
对于泊车的车位感知,这里选了一个泊入的场景,红线代表入口线,黄色的x代表占用,黄色的小框是停车场的立柱,草绿色的是轮档器。
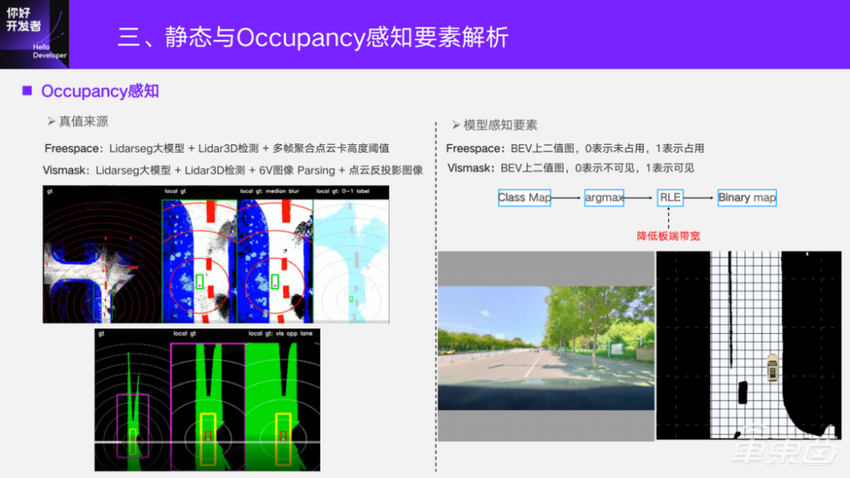
接下来讲Occupancy的感知。首先说一下Occupancy是一个基于征程5的2D占用图,是一个二值图,0表示未占用,1表示占用,我们内部称它为Freespace。传统的Freespace是图像分割做后处理,去计算在BEV下的可行驶区域。而BEV上做就比较自然一些,直接在 BEV上去输出一个这样的二值图。它的真值依赖Lidar分割模型+检测模型+多帧聚合点云卡高度的阈值,去获取地面上的一些障碍物。Lidarseg主要是先得到基础面,把路平面这一类作为可行驶区域;Lidar3D检测是去补充白名单的动态障碍物的占用真值。
另一个输出是Vismask。它主要描述的是自车当前时刻在图像里能够看到的区域,也用到了Lidarseg模型和3D检测模型。图像分割结合点云的反投影,就可以获取到在 BEV下能够看到的点,根据语义和相机参数算射线,就能算到图像里能看到的点在自车坐标系铺成的面,然后以点云高度方向拍平就得到BEV上的可视Grid点。为什么需要3D检测呢?是因为射线打到点云的时候是一个面。我们希望面边界的整个目标都是可视的,所以需要3D检测框去把边界的目标补充上,这样就获得了这两个任务的真值。感知模型是一个比较简单的二分类模型,Vismask的0表示不可见,1表示可见。
因为这两个任务是稠密输出,在板上实际做这件事情时,它的带宽占用比较大。通常我们会采用一个游程编码(Run Length Encoding,RLE)进行结果压缩。比如Freespace,以下图为例,它在一个连通区域内的取值都是一样的,用游程编码去降低感知结果从征程5的BPU传输到CPU的带宽,在CPU做一个反解析,就能得到最终输出的二值图。
这里有一个可视化的视频,左侧长条是对栅栏的响应。这是专门构建的一个评测集,包含婴儿车、倒下的锥桶等。这里 Freespace主要是去补充非标障碍物的感知。另外,下游闭环使用时也反馈Freespace对路沿的表征也是比较好用的。
04
动态感知预测端到端与芯片部署
下面介绍一下动态感知预测端到端的方案以及芯片部署情况。
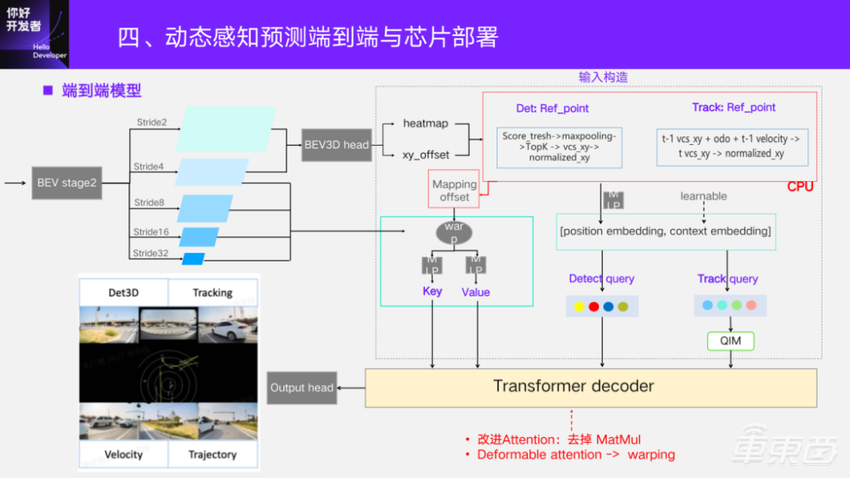
端到端模型,如前面框架图里的,是在BEV3D后面接几层Transformer decoder,做动态端到端要素的输出。前面复用BEV二阶段提取的多尺度的特征,有一个BEV3D的检测head,回归heatmap和到精确位置的偏移,得到可能存在的目标位置。
对于Transformer head而言,就看第一层它的输入的Q/K/V怎么来?这里有一个输入的构造部分。首先,“Q”分为检测query和Track query。检测query的position embedding,是从BEV3D head里解析出来的位置,去过MLP得到的 position embedding;context embedding是可学习的,随机初始化就可以。
对于Track query的position embedding是会用到上一帧的位置,结合帧间的自车运动对齐到当前帧,消除自车的运动。再去结合它本身的上一帧的速度估计结果,去估计在当前帧的位置,也过MLP去得到Track query的position embedding。它的context embedding在最开始也是随机初始化的、可学习的,这是得到了“Q”。
“K”和“V”对于BEV来说,BEV上的像素坐标和VCS下的坐标位置是有固定映射关系的。所以根据参考点的位置可以反向地算到它在BEV多个尺度上的像素坐标。query也从0到N-1去排序,它就有一个index,这样两个坐标做差可以算到两者之间的映射关系。再通过warping算子,也就是grid_sample算子,去反向地索引BEV区域特征,之后过MLP生成 “K”和“V”,这样端到端head输入就构建好了。
这里的Transformer,里面一个区别点就是对在征程5上的量化和效率做了改进,去掉了MatMul矩阵乘算子。这里对通常采用的Deformable attention,是用了warping的实现方式去替代。
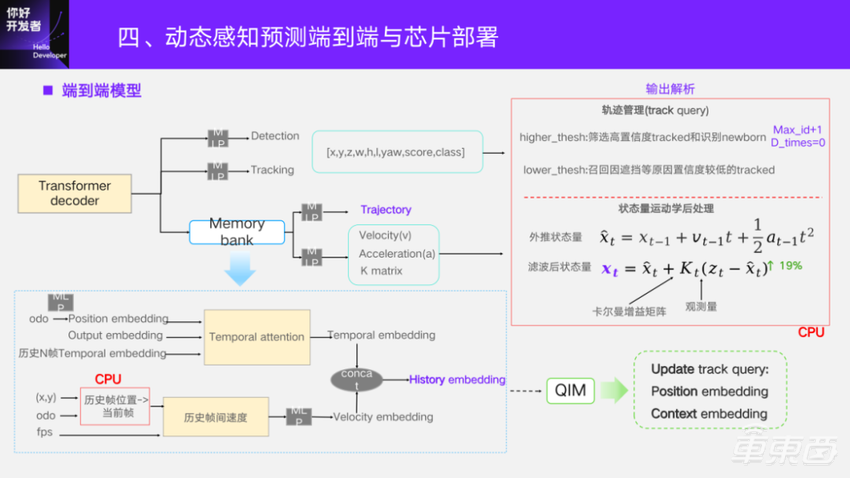
对于端到端head的输出层其实就是几个MLP。其中轨迹和速度的输出,前面会过Memory bank是为了获取历史信息。这里输出的轨迹的点也是帧间的位移情况,速度描述的也是未来帧间单位时间的位置变化。我们认为这些变化都不是突变的,它具有平滑性,所以用历史的信息。
历史的 embedding是由两部分构成。第一部分是在Memory bank里会存下N帧的历史帧的odometry,还有N帧的历史的 Transformer decoder输出的query的embedding。当前帧的query,对每个目标做当前帧的和历史帧的时序上的attention。做完之后,各目标间也会做self-attention,最后我们定义它为Temporal embedding。另外添加了速度的embedding,它是怎么来的呢?就是把历史N帧框的位置,通过自车运动的odometry转到当前帧下,得到历史帧在当前帧下的位置,消除自车运动,得到帧间的偏移,结合系统的帧率可以推出一个时间差,就能估计历史的帧间速度,同样过一个MLP,就可以得到速度的embedding了,两者做一个简单的concat,就得到了最终的 History embedding,输入到轨迹和速度head里面去。
对于模型输出之后,也会有一部分在 CPU里解析。对于Track query和Detect query,本身模型输出会解析出位置、长宽高、朝向角、Score置信度等。轨迹管理的作用是筛选出下一帧的Track query。这里设定了两个阈值。一个比较高的阈值,是从所有的query里面筛选出置信度比较高的tracked,也就是已经跟踪上的query,并且识别出当前帧新产生的目标。针对新产生的目标,赋予一个当前最大id值+1,并且赋予它消失时间是初始化0。对于设置低的阈值,是想把之前跟踪上的,但是在当前帧因为遮挡等原因导致置信度比较低的这些目标,召回来再看一下。如果它能够大于这个阈值,并且消失的时间没有大于设定的时间,就把它继续保留下来。如果消失的时间(disp_times)已经大于设定的可丢帧数阈值,这个目标我们就确定在这一帧把它丢掉。
对于速度的解析,模型本身是可以直接输出的,出来之后会加运动学的后处理。这里的“z”是前面输出的长宽高以及速度(属性),我们称它为观测量。模型还会去学卡尔曼的增益矩阵,避免了在CPU上去计算 “K”,最后给到下游的是滤波后的状态量。这个操作相比于不加滤波的,在速度精度上面有19%提升。从可视化表现上面来看,速度确实经过这个之后表现得更加平滑。在更新下一帧Track query的embedding的时候,会用到 Memory bank里面生成的历史embedding。QIM这一块细节就不展开了,可以参考一下MOTR的实现。
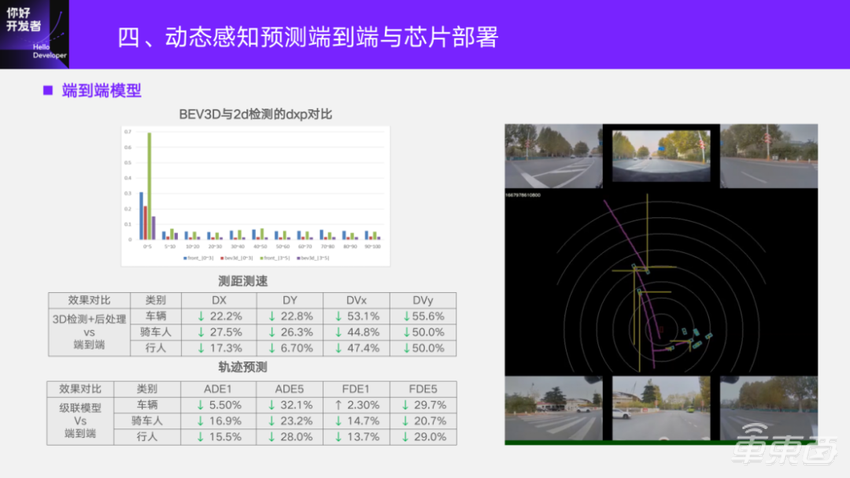
进一步看一下端到端模型的性能。端到端对比的是只做检测通过后处理去做跟踪和速度估计。这里对比的baseline检测,已经是 BEV上的3D检测。相比原本的2D检测,在测距上已经有非常明显的优势了。蓝色和绿色是2D检测在不同距离段的纵向误差百分比,红色和紫色是 BEV3D的,可以看到在这个比较好的baseline的基础上,端到端的模型是相对BEV3D更有优势的。
首先看一下测距测速。端到端在动态的三类障碍物上,测距和测速都是有明显的优势。这里的误差越低越好,以及这里是误差下降的百分比,尤其是速度优势特别明显。轨迹对比的是一个级联的模型,它的输入是 BEV上3D检测的动态后处理,还有车道线的静态后处理做完环境重建的一些向量信息,是一个单独的轨迹预测模型。端到端输入的是图像,直接输出的是轨迹。两者相比,在这个点列的位置误差上面,端到端在三类上面也是有明显的优势的。
这边也是给了一个可视化的视频。图里面的框就是目标,黄线是代表横向和纵向的速度,粉线是轨迹。可以看到从右侧过来的目标在经过前方的时候,虽然被这里的目标遮挡,但它还是能稳定出现的。对于刚才说的速度优势,尤其是像停在旁边的这一类目标,一般如果是检测框,一旦有抖动超出了后处理能cover的范围,就会出现一个比较大的速度,从而去触发一条轨迹,造成自车的一些点刹等现象。像这里停在旁边的是非常稳的,速度基本上都是和实际是相符合的。
05
实车部署与闭环验证
最后一部分介绍一下实车闭环的时候,跟模型相关的几个关键问题。

首先,部署前肯定要做模型的量化和编译。专业的量化的流程以及方式方法,我们后续也安排了公开课做分享,我这里主要是从一个用户的角度看这个事情。
对于一般的模型,像基于CNN的,我们直接单任务float,训完之后直接训qat,这些基本上不掉点。多任务中间会加一个freezebn,使得统计出来的bn能够适用于各个任务。
对于复杂的模型中间会加一步calibration。这里想要重点说的就是 calibration。以我们做端到端模型部署为例,就单任务模型而言,前期端到端直接 float训qat,掉点是非常多的。请教了工具链的同事之后,建议我们做calibration。但calibration做完发现 qat虽然有大幅的提升,但还是和float有较大的差距。工具链的同事建议去固定住 weight或者feature的scale。实际的来看固定feature的scale是比较有效的,但尽管这样也没有完全解决端到端上面几个任务的qat输出的问题。
那问题出在哪?也是趟了一些坑,其实现在想就很简单。我们要去算合适的feature scale,做calibration时要选择恰当的数据。比如速度,我们前期用的是城区场景的数据去做速度的feature scale的估计,发现训出来的qat模型在高速场景下的 qat指标相比于 float掉点比较厉害。后来通过工具链的工具,一层层分析模型发现确实找不到模型上的问题。如果模型实在没问题,那就是数据的问题了。最后我们采用了一个高速的数据集。因为calibration本身训练步数不多,所以要选择能够覆盖感知的量,能达到最大值和最小值的上限下限,才能估计出比较合适的量化的scale。
尽管做了这一步操作,量化问题已经大大解决了。但是,工具链的标准一般是 qat和float的差距不能大于1%。做完这两步,它还是达不到这个水平。那么还在哪里出了问题呢?后来也是一顿摸索,发现在BEV上做3D感知的很多量都是有物理意义的。最终结论就是对一些有物理意义的计算层固定scale。固定的scale从哪来呢?比如刚才前面提到query索引 BEV上的feature有warping操作 ,计算offset的两个输入是有明确的物理意义的。当模型结构确定之后,BEV上的 meshgrid的最大值、最小值,还有query index的最大值、最小值,都是已经定了,这样就可以算出来矩阵的最大值、最小值,进而算出固定的scale。
还比如以odometry作为模型输入,calibration的数据可能是以中等速度行驶采集,但实际大规模数据训的时候,自车运动的速度也可能发生变化。所以对这种有明确交规规定的物理量,也能够拿到最大值、最小值。用类似这个思路,去检查网络里面有物理意义的一些数值计算的层,把固定的scale算出来。通过这几个操作解决了端到端模型的qat问题,也是趟了很多坑趟出来的经验,来跟大家分享一下。
做完了量化就是编译。编译就是编译器直接qat转了中间格式hbir,最后再得到真正板上部署的 hbm格式,具体的细节也是后续有分享去介绍。这里主要是说一下BEV感知实际部署时候的表现。
大范围的BEV是以前向100、后向30、左右各50的感知范围,小范围是以前向20、其他三个方向10米的感知范围,去做BEV上的要素感知。在征程5单核上,比如泊车小范围,单核、单帧的多任务模型可以达到70fps以上;行车的大范围也可以达到30fps以上。就算加了端到端,直接输出到轨迹预测的模型也能达到20fps以上,这是在单核的情况。而征程5上是有双核,在模型调度上帧率可以进一步提升。

部署的时候检验的是模型的泛化性。因为客户的车的车型是不一样的,相应的相机安装位置、朝向可能都有差异。我们的BEV模型,特别是在原型开发阶段,有很多前期验证的客户,所以一个模型尽量能够支持多款车型的部署,这对模型的泛化性要求很高。我们也探索了很多,最后发现前面介绍的四平面的空间融合方法,一开始已经打了一个比较好的基础。这里举的例子是训练数据都是用SUV采集的,评测的时候用轿车的数据。如果是单平面,它相比四平面已经有7个多点的掉点了。
在四平面比较好的泛化的基础上,我们再去开发一些训练上面的增强策略。这里比较有效的两个方法:一个是BEV模型一阶段对图像进行摄像头rpy的扰动,模拟车辆行驶的过程的颠簸情况,做图像增强;另外,是在做视角转换的地方假设平面,然后对camera出 VCS的平面上做平面增强,也是假设 rpy的扰动。
带上这两个扰动策略,在SUV车型采集的训练集训,在轿车采集数据集上测,可以达到这样的性能(AP 72.60),和我们加入了大概20来天采集接近100万的数据去训的一个适配轿车的模型,在同样的评测集去评,达到了相近的性能。所以由这几个策略feature保证了我们现在这一套BEV感知模型,在实际部署时的泛化性。
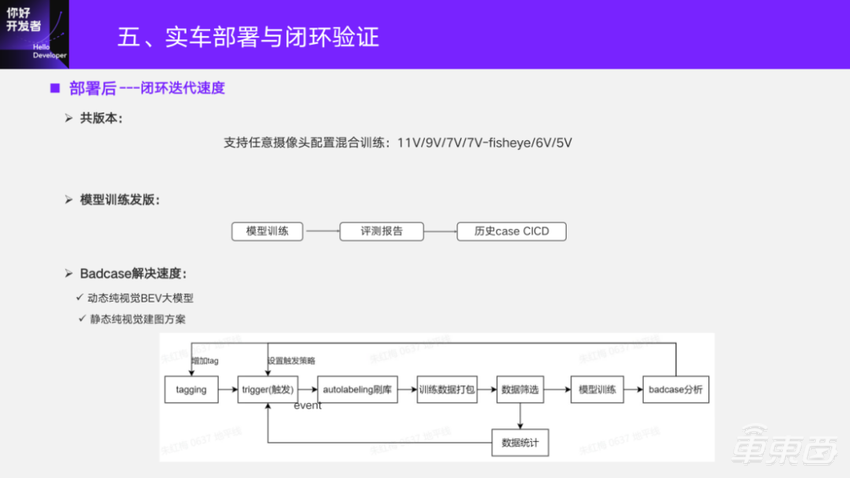
部署后考验的是模型闭环迭代的速度。特别是在前期原型方案验证阶段,通过共版本去支持不同的实车安装部署的demo闭环验证。对于BEV训练框架而言,可以支持任意摄像头配置。比如说11v/9v/7v,7v里面可能把4v周视替换成4v鱼眼,或者是其他任意多个视角,都可以参与到模型训练当中。部署的时候按相应的摄像头配置去做编译,就可以去做相应的测试。
另一个就是模型的训练速度,尤其是时序融合上来之后,在不优化的情况下,假如单帧训练5天,10帧是线性的,会带来10倍的训练时长,这肯定是不能接受的。我们肯定要做优化,也有框架开发的同学专门对我们进行指导去做优化。目前,在优化后训练速度提升了56%。
具体来说,目前多任务发版,十几个任务头的多任务,大概时序端到端训练能够在一周内完成。后面的评测或者是历史的一些数据的case CICD都是自动化的,从而保障了训练发版这一步的高效性。
另一个重要的因素,特别是在实车测试前期都会反馈一些不work的case——Badcase数据回来。怎么把这些数据用到训练里面去呢?一般有两种针对Badcase的优化:一种是从采集数据里面挖掘,这是比较常规的;另一种是能够把返回的Badcase数据直接用起来。
对于像2D感知,之前我们做量产这一条链路都是比较成熟的。对于BEV感知,它的区别是看刷库的模型怎么来的,或者送标的数据是怎么来的。对于动态而言,用纯视觉大模型,不受板上op和算力限制。我们有大模型团队,专门开发的纯视觉BEV大模型,目前也已经用在动态的Badcase处理链路里面,去生成一个伪GT参与训练。静态这块有纯视觉的建图方案,同样可以将底图送标,目前也已部署到BEV上静态感知Badcase链路里面了。其实模型部署后,很多都是一些基建问题。目前,地平线对于BEV感知的基建基本成熟了。
今天我的分享就是这些内容,主要是想传达几个意思。首先,基于征程5芯片确实能干很多事情,我们在上面也干了很多事情。对于BEV感知方案而言,可以看到我们有比较好的baseline去做参考进行迭代,这样得出来的结论也是相对solid。
另外,如果线上有同学正在基于征程5做开发,或者是即将基于征程5芯片做开发,当你们遇到量化问题的时候,不要太早地放弃,除了从模型结构这个角度考虑,多从数据的物理意义角度去分析,给它合适的scale。
最后,祝大家开发顺利,我今天的分享就到这,谢谢大家!