车东西(公众号:chedongxi)
作者 | 小崔
编辑 | Juice
“FSD的安全指数将是人类驾驶员的10倍,汽车价值将提高5倍!”
这是昨天马斯克在股东大会上就特斯拉FSD发展前景的表态,马斯克表示,目前FSD的发展速度还在逐步提升,通过软件更新,特斯拉可以从需要人工干预转向完全自动驾驶,这是一个非常重要的里程碑。
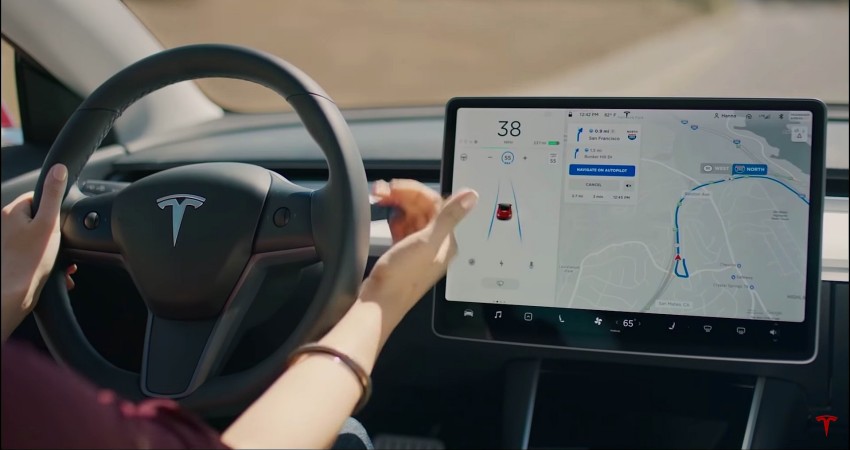
▲特斯拉FSD Beta近几年的发展速度
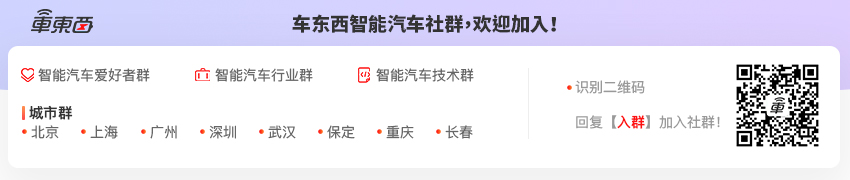
而马斯克口中所说的里程碑时刻,或许就是特斯拉FSD Beta V12版本正式上线使用时候。10天前,马斯克曾发布推特,称特斯拉将发布FSD Beta V11.4版本,该版本将采用端到端的人工智能技术,而马斯克本人也表示V11.4版本实际上便是V12版本。
如果马斯克所言能够完全落地,不仅意味着特斯拉FSD即将进化至完全体,而且还意味着特斯拉将在自动驾驶领域端到端这一技术路线的贯彻上持续领先业内其他玩家。
端到端,正在成为自动驾驶玩家的另一条技术路线选择!而特斯拉,正在成为落地这一技术路线的排头兵。
实际上,端到端并不是自动驾驶领域独有的说法,其本身是深度学习的一个概念,指的是一个AI模型,与此前大火的ChatGPT类似;而特斯拉FSD的端到端技术实际上就是利用了这样一个大模型来做到感知决策一体化。
与传统自动驾驶路线不同,端到端大模型取代了此前用于感知、描述、预测以及规划的多个模块,让自动驾驶直接从一端输入图像数据,一端输出操作控制,更接近人类的真实驾驶。
端到端的大模型也并不是特斯拉“一家之言”,英伟达团队在2016年通过监督学习首次实现了智能驾驶的端到端控制输出;小鹏也自称XPILOT是国内唯一拥有端到端自研技术并实现量产的自动驾驶系统。
那么,特斯拉采用的端到端技术路线究竟是怎样的呢?其在运用过程中有何爽点和痛点呢?车东西经过一番摸索终于从中理清了一些思绪。
一、基于深度学习 自动驾驶中的ChatGPT
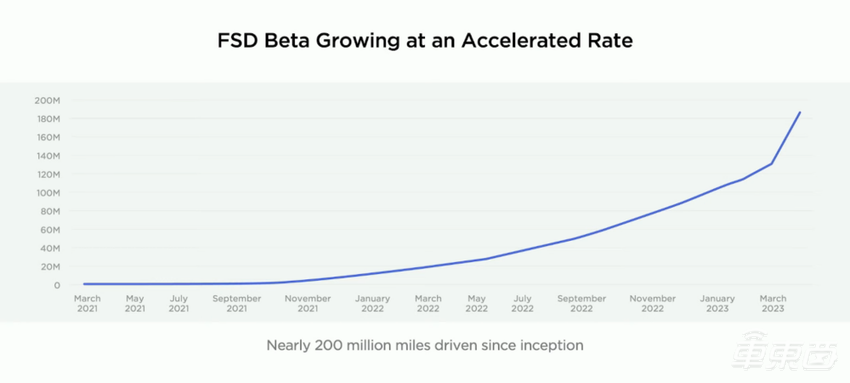
目前的自动驾驶技术大致可以分为两类,一类是间接感知方法,即传统主流驾驶方案,通过多个工程模块进行组合完成智能驾驶任务。这一方案下,自动驾驶系统工作的流程为:摄像头和雷达感知收集图像数据,然后各模块将采集到的数据进行诊断和规划,最后向车辆发出控制指令。
▲传统多模块解决方案(图源网络)
这就好比甲乙两个人开一辆车,甲只负责监测周围的环境,乙只负责控制汽车,在整个行驶过程中,甲先监测周围环境,根据周围环境判断汽车该往哪个方向走,随后向乙传达信息,乙只需要根据甲的信息来操作方向盘、制动器和刹车。
传统的自动驾驶方案数据处理模块多、步骤多,流程比较复杂和割裂,甚至说甲的工作还需要更多的角色来承担,比如可以划分为视觉和听觉两个方面,而视觉工作还可分为前后方和左右方图像收集。
而另一类驾驶技术便是行为反射方法,即采用端到端技术方案,该方案基于深度神经网络,通过摄像头采集驾驶场景的信息,将其作为深度卷积神经网络模型的输入,再不断对网络模型进行训练,得到学习好的网络参数,从而对智能车方向盘转角进行预测。
这一方案将此前各模块的感知和规范集成到一个大模型之中,而采集到的数据直接从一端输入至大模型,大模型能够根据数据计算迅速做出判断从另一端向车辆发出控制行为。
这一驾驶方案更加接近最真实的人类驾驶,只需要一个人来开车,从眼睛看到到双手转动方向盘、脚踩刹车或制动板,整个过程一气呵成,而这背后最关键的因素便是人类的大脑中枢神经系统,而端到端大模型的作用则类似于人类的大脑中枢神经系统。
另外,我们还可以从另一个角度来理解端到端技术方案,那便是类比此前爆火的ChatGPT。ChatGPT是一个典型的端到端AI大模型,只需要输入文字语句,直接就能得到回答。
ChatGPT的两端分别为文字语句和回答,而特斯拉自动驾驶的两端则为道路场景图像和车辆控制参数,道路场景图像由摄像头或雷达采集,而控制参数则包括方向盘转角、油门、刹车和速度等数据,中间便是特斯拉端到端大模型。
不过,与ChatGPT不同的是,自动驾驶领域对端到端大模型的要求更高,可试错性更低。ChatGPT的语句问答出现错误造成的损失较小,而自动驾驶的端到端大模型出现错误则会造成严重安全驾驶隐患,所以二者的应用并不在同一个维度。
那么,端到端大模型如何做到无限接近人类真实驾驶的自动驾驶呢?答案便是深度学习和强化学习。
▲深度学习(图源网络)
深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字、图像和声音等数据的解释有很大的帮助。它的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。深度学习是一个复杂的机器学习算法,在语音和图像识别方面取得的效果,远远超过先前相关技术。
▲强化学习(图源网络)
强化学习则是用于描述和解决智能体在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。
特斯拉采用的端到端大模型最大的改变便是可以不断进行学习,车主每使用FSD行驶一公里,大模型都可以收集更多数据,并随着时间的推移在自动驾驶行为方面有所改善,而这或许也和特斯拉的影子模式有一定的关联。

▲特斯拉影子模式
为实现自动驾驶技术的自我演进,特斯拉开发了影子模式。每一款特斯拉量产车都配备了影子模式,影子模式负责在用户驾驶过程中采集各类驾驶数据,其中包括高价值的corner case数据,而特斯拉采集的数据包括车辆的位置、速度、方向和加速度等信息,这些数据将被存储在特斯拉的数据中心中,然后由数据引擎进行分析和处理。
而“大模型”往往包含了上亿的参数量,例如前面提到的GPT,从GPT-1到GPT-3,模型的参数量从1.1亿个增长到了1750亿个,几年的时间内增长了一千多倍。而模型参数量的不断提升也会让模型的能力持续提高。
二、避免级联误差 近乎黑盒可解释性差
与传统的多模块处理方案相比,特斯拉端到端人工智能方案最大的优势便是可以避免级联误差。
传统的多模块化架构其实是一种流水线工作,后一个模型的输入参数是前级模型的输出结果,如果前级模型输出的结果有误差,就会影响下一级模型的输出,导致级联误差的出现,最终影响整套系统的性能。而端到端的大模型输入一端有且只有摄像头采集到的驾驶场景信息,也就不存在级联误差。
另外,端到端人工智能方案还省略了大量繁琐的中间步骤,简化了流程,基于组件的系统工作更少。
当然,端到端大模型还存在诸多痛点,而其中最大的痛点便是可解释性差。
AI界有一个词叫做“涌现”,意思是当模型突破某个规模时,性能突然显著提升,表现出令人惊艳、甚至是意外的能力。而之所以称之为“涌现”,是因为这种情况是不可控、无法预知的,即便一个模型发生了“涌现”,人们也不知道其内部发生了什么,是因为什么导致了能力的巨大变化。
而端到端大模型也存在可解释性差的问题。人们对这个模型内部知之甚少,甚至不理解这个模型的工作原理,是一个黑盒。
▲黑盒示意图(图源网络)
当遇到失败例子时,通常的做法只能是添加更多的数据,期待重新训练的模型能够在下一次通过这个例子。
端到端大模型由数据驱动替代规则驱动,不再按照“if…then…”的规则运行,而是根据不断收集到的人类驾驶真实数据进行判断,虽然能做出正确的决策,但方法和理由是什么都不清楚,具体依照的哪些数据更无从得知。
即便出了差错,由于端到端模型是作为一个整体工作的,因此我们几乎无法找到模型中应该为这次失败负责的“子模块”,也就没办法有针对性地调优。只能通过不断的训练、调参、增加参数量,来尽可能地提高模型的准确率,但100%的安全率似乎永远也无法达到。
第二个痛点则是端到端驾驶模型很难引入先验知识。目前的端到端模型更多地是在模仿人类驾驶员动作,但并不了解人类动作背后的规则。想要通过纯粹数据驱动的方式让模型学习诸如交通规则、文明驾驶等规则比较困难。
另外,端到端大模型也很难恰当处理长尾场景。对于常见场景,我们很容易通过数据驱动的方式教会端到端模型正确的处理方法。但真实路况千差万别,我们无法采集到所有场景的数据。对于没有见过的场景,端到端大模型的性能还很难保证。

▲长尾场景(图源网络)
最后,端到端驾驶模型通常通过模仿人类驾驶员的控制行为来学习驾驶技术。但这种方式本质上学到的是驾驶员的“平均控制信号”,而“平均控制信号”甚至可能根本就不是一个“正确”的信号。比如,面对会车情况时,本车是选择让旁边车道的车先走,还是抢在其之前走,司机本身也是有两个选择的。而当前情况下的概率分布真值又很难获得,这又非常依赖大规模数据的积累和数据真值的清洗。
毫无疑问,端到端大模型最厉害之处便是无限接近人类真实驾驶,而背后的痛点也不少。如果特斯拉真的能够做到无限接近人类真实驾驶水平,那么这些痛点也就不在话下,可谓是“一白遮三丑”了。
三、研发已久 特斯拉或将率先量产
事实上,端到端大模型在自动驾驶领域研发已久,业界和学界都曾积极参与其中。
1988年,ALVINN首辆运用神经网络控制的自动驾驶汽车上线,ALVINN是一个3层的神经网络,它的输入包括前方道路的视频数据、激光测距仪数据,以及一个强度反馈。该模型成功地以0.5米每秒的速度开过一个400米长的道路。
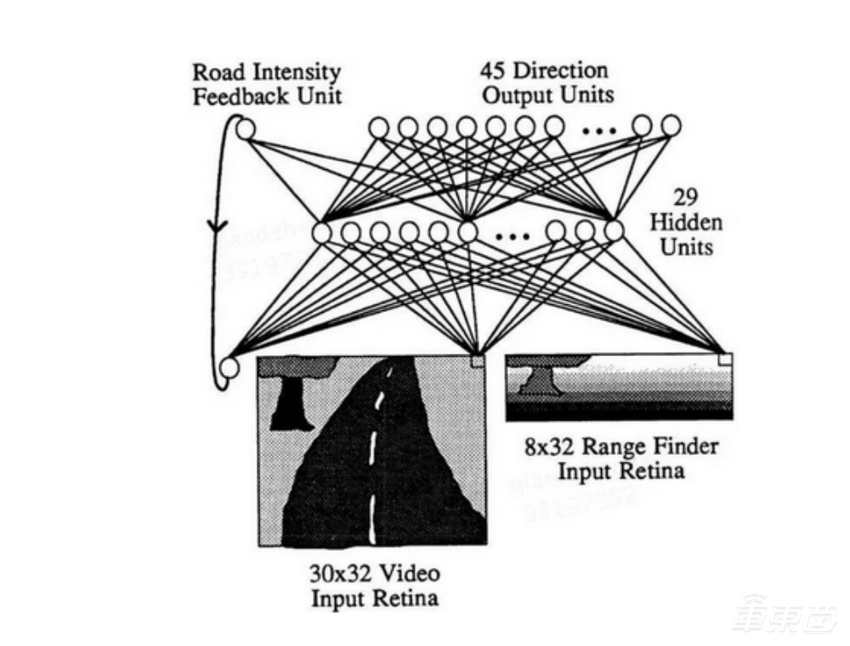
▲ALVINN的网络结构示意图(图源网络)
1995年,卡内基梅隆大学在ALVINN的基础上通过引入虚拟摄像头的方法,使ALVINN能够检测到道路和路口。
2006年,LeCun研发出一个6层卷积神经网络搭建的端到端避障机器人,其方案为端到端直接预测,输入为双目图像,输出为转向角度。
2016年,英伟达开发出PilotNet。该模型使用卷积层和全连层从输入图像中抽取特征,并给出方向盘的角度。另外,NVIDIA还给出了一套用于实车路测的计算平台NVIDIA PX 2。
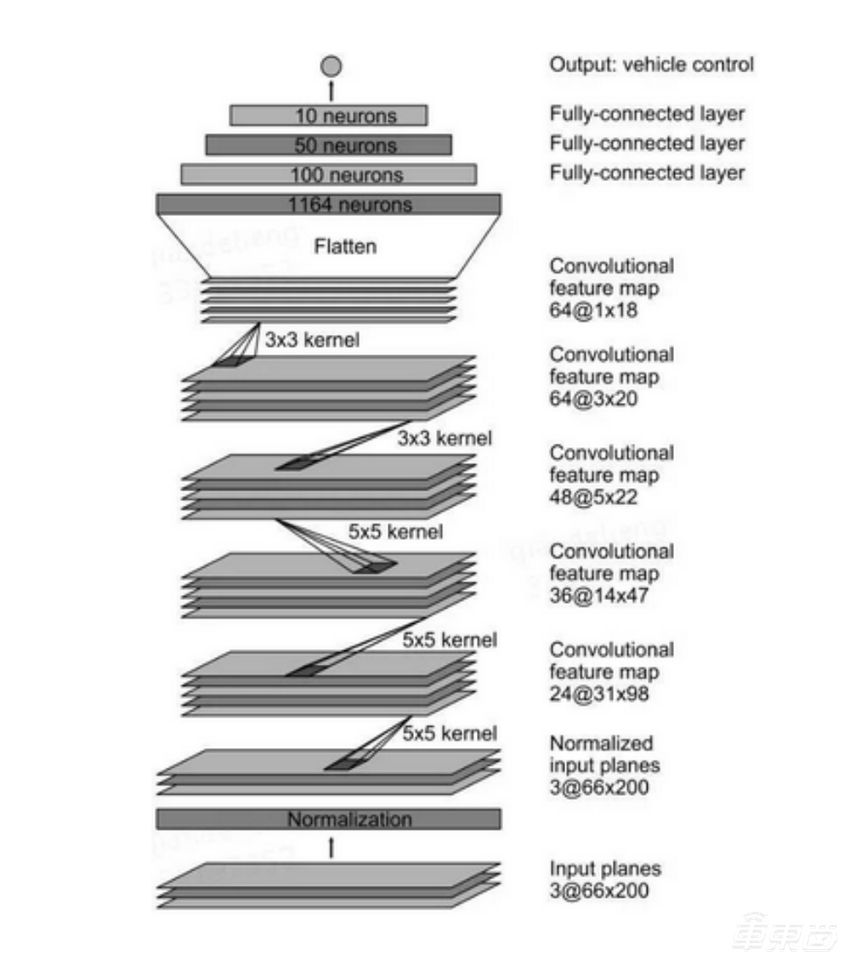
▲PilotNet网络结构示意图(图源网络)
英伟达团队通过监督学习首次实现了智能驾驶的端到端控制输出。该算法以RGB视频图像作为输出,省略了中间感知、决策、控制等环节,直接输出方向、油门、制动等动作,虽然使用监督学习训练的模型在大部分的环境下有良好的行驶表现,但需要体量庞大的人工标注的数据。
在此之后,加州大学伯克利分校提出了FCN-LSTM网络,其首先通过全卷积网络将图像抽象成一个向量形式的特征,然后通过长短时记忆网络将当前的特征和之前的特征融合到一起,并输出当前的控制信号。值得指出的是,该网络使用了一个图像分割任务来辅助网络的训练,用更多监督信号使网络参数从“无序”变为“有序”。
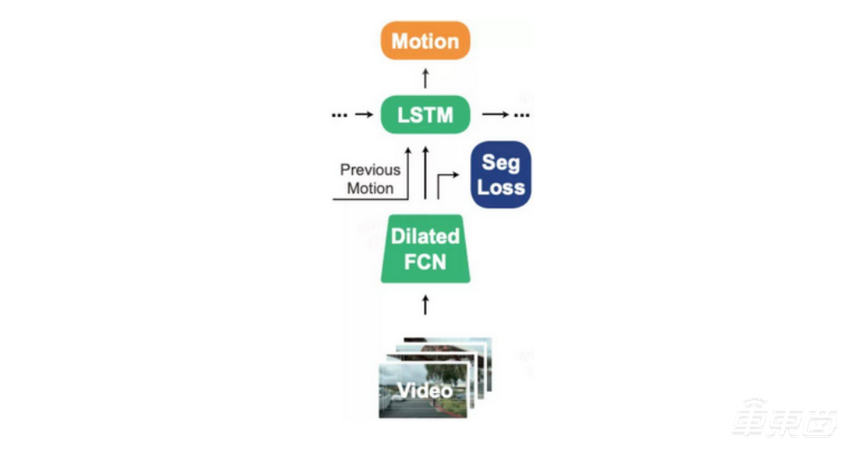
▲FCN-LSTM网络结构示意图(图源网络)
另外,罗彻斯特大学提出的Multi-modal multi-task网络不仅给出了方向盘的转角,而且给出了预期速度,也就是包含了“纵向控制”,完整给出了无人车所需的最基本控制信号。
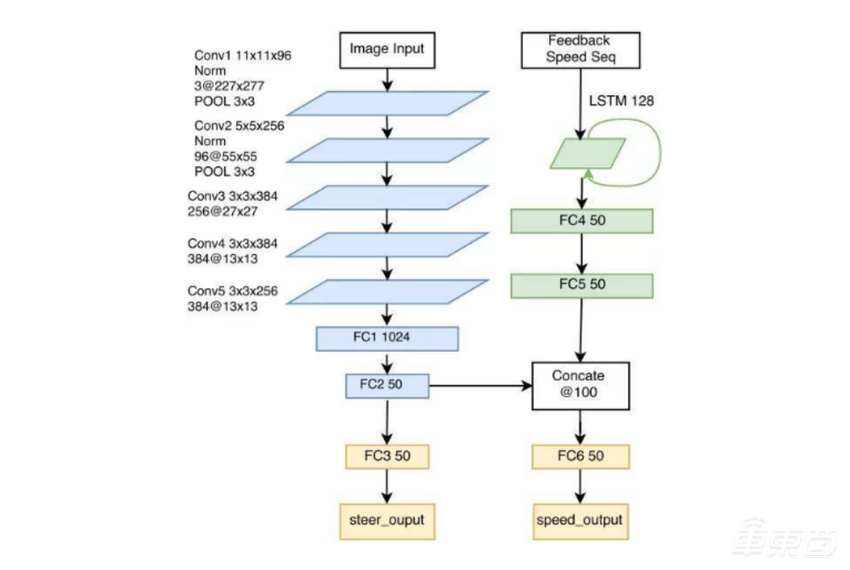
▲Multi-modal multi-task网络结构示意图(图源网络)
在国内,北京大学提出了ST-Conv + ConvLSTM + LSTM网络,该网络大致分成两部分,即特征提取子网络和方向角预测子网络。特征提取子网络利用了时空卷积、多尺度残差聚合、卷积长短时记忆网络等搭建技巧或模块,方向角预测子网络主要做时序信息的融合以及循环,由于无人车的横向控制和纵向控制具有较强的相关性,因此联合预测两种控制能更有效地帮助网络学习。
而在今年4月11日,毫末智行发布了自动驾驶界的首个生成式预训练大模型——DriveGPT雪湖·海若。据了解,DriveGPT雪湖·海若已完成基于4000万公里驾驶数据的训练,参数规模达1200亿。
按照毫末智行的说法,ChatGPT的输入是未写完的句子,输出是续写完成的句子,而DriveGPT的输入是某个场景下前序几秒内的驾驶环境,输出是该场景下后序几秒内的驾驶环境。DriveGPT将输入与输出相连,就组成了完整的驾驶场景时间序列,包括在序列中任何一个时刻,周围交通环境的状态、其他交通参与者的状态以及自车的状态。

▲DriveGPT雪湖·海若(图源网络)
不过,目前只有特斯拉表示已经在FSD Beta V11.4版本中采用端到端的人工智能方案,而V11.4版本目前在海外已经开放使用,V12版本也即将上线。
结语:特斯拉率先实现端到端自动驾驶
光线从一个人的眼睛这端输入,驾驶操作从同一个人的手脚端输出,端到端模型能够随着数据训练的增加无限进化。这几乎是未来自动驾驶的最理想方案,更接近人类真实的自动驾驶,并且比人类驾驶的安全性更高。
就在今天的股东大会上,马斯克还对FSD的发展十分看好,并表示未来FSD的表现优秀程度会是人类司机的10倍。而这一切,也都将依靠端到端的大模型。
从人类的驾驶行为模仿出发,到不断超越人类的驾驶行为,端到端大模型正在改变自动驾驶行业的发展。