








车东西(公众号:chedongxi)
作者 | 赵行
编辑 | 晓寒
裁员、破产案例频发,L4自动驾驶要不行了?
国内最早进行自动驾驶技术产业化尝试、拥有最强大自动驾驶团队和全球最大规模应用落地的百度站出来了,大声说了一句:NO!
就在本周二,百度举行了Apollo Day技术开放日活动。虽然受疫情影响改为了线上举行,但百度Apollo却破天荒地一次性摆出来六位高级专家,对这次活动的重视程度极高。
感知、决策、地图、数据、芯片等领域的六位技术专家先后登台,详细向外界介绍了百度的自动驾驶领域取得的最新技术进展,涉及文心大模型的应用、学习型决策系统、轻量化高精地图技术的突破,以及新的数据闭环架构和云端AI芯片。
这些领域加起来就是自动驾驶系统的最核心部分,这也意味着百度是想告诉外界:自己在自动驾驶的各个关键环境都实现了新的技术突破,离无人驾驶的大规模商用只有咫尺之遥了!因此,百度在活动现场也宣布将在2023年打造全球最大的全无人自动驾驶商业运营区。
那么百度本次展示的技术到底能解决哪些实际问题,在业界属于什么水平?又是否真的像百度所言那样,到了能推动无人驾驶规模商用的地步了呢?
为了回答这些问题,车东西邀请到了一位硬核专家——清华大学交叉信息研究院助理教授,博士生导师赵行博士进行解读。

▲清华大学交叉信息研究院助理教授,博士生导师赵行博士
赵行教授深耕自动驾驶领域多年。
早在2015年于MIT麻省理工学院读书期间就联合开发了第一门自动驾驶课程,后被推广到全世界十余所高校进行应用教学。其在MIT攻读博士学位期间师从AI+决策系主任Antonio Torralba教授,主要研究方向为计算机视觉,多模态和多传感器的机器学习。
2019年博士毕业后,赵行加入全球自动驾驶领域的领头羊Waymo担任研究科学家,提出了自动驾驶行为预测中一系列框架型的工作,为行业大多数公司所使用或借鉴。其本人也入选2020年福布斯中国U30科学精英榜。
赵行于2021年回国,加入清华大学担任助理教授,研究领域涵盖自动驾驶的整个算法栈,以及多模态和多传感器的机器学习。在国际顶级期刊和会议发表论文共计40余篇,Google Scholar引用共计9000余次。研究工作曾被BBC,NBC, 麻省理工科技评论等多家主流科技媒体报道。
他在清华大学组建和指导MARS Lab课题组,主要研究兴趣为自动驾驶,多模态学习和计算机视觉。提出了“以视觉为中心的自动驾驶VCAD”方案,被业界广泛采纳并落地应用。
以下为赵行教授对百度Apollo Day上多项亮点技术的深入解读。
近日,百度Apollo Day请来了自动驾驶各个板块的负责人,给大家讲解了百度在开发自动驾驶过程中的方法和思考。我选取了几个开放日中几个有意思的技术点来给大家做进一步的解读。
1、感知-文心大模型
2、高精度地图
3、预测决策一体化
4、数据闭环
一、引入文心大模型 进一步提升感知能力
这次开放日最大的亮点之一属于感知,感知方面有两个关键词,第一个关键词是多模态,第二个关键词是大模型。
首先,王井东介绍了百度的多传感器融合和分工方案,如下图所示。整体的思路是按照感知距离进行模型划分:对于远距离物体,使用相机进行感知;对于中距离物体,采用最近最流行的BEV方案进行多传感器融合感知;对于近距离物体,采用鱼眼相机的BEV方案进行补盲。
对于BEV多模态融合的方法,最近两年涌现出很多方案,各位同学可以阅读论文BEVFusion[1],FUTR3D[2],我在此不展开介绍。
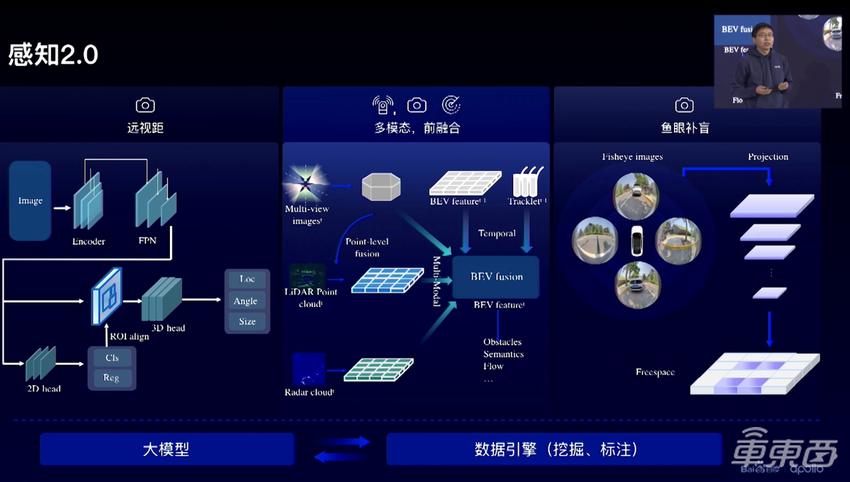
▲根据距离进行感知模型划分
对于多传感器融合的效果,王井东展示了一个有意思的例子。在点云图中,我们容易误识别洒水车的洒出的水是车辆;在多模态融合后,我们可以很好地避免这样的误检测。

▲多传感器融合识别洒水车的水露
接下来我们看大模型。大模型是AI学界最热的关键词,那么大模型可以解决自动驾驶中的什么问题呢?主要有两方面:1. 远距离检测;2.长尾物体识别。百度采用了两种大模型技术,分别解决这两个困难。前者聚焦几何,后者聚焦语义,各有所长,下面我们来分别讨论。
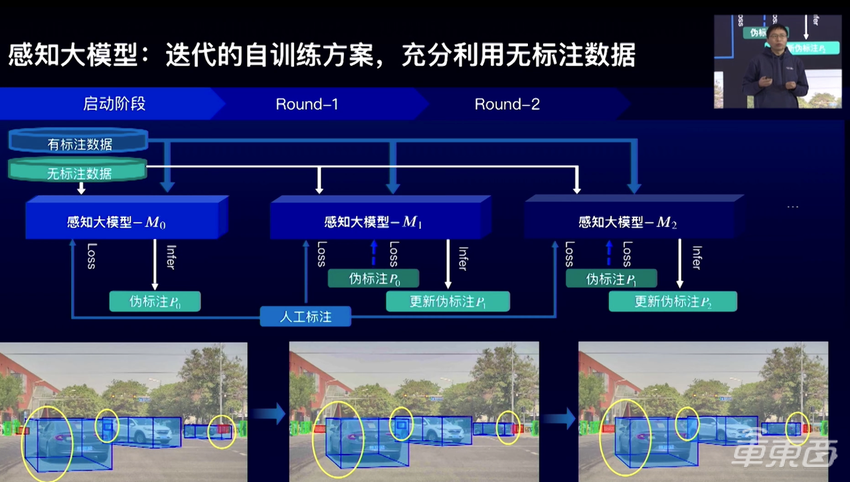
▲感知大模型的自训练方案
1、“文心大模型-感知大模型”。
感知大模型主要用于提升3D感知能力,模型大了,要求的训练数据自然多,然而3D感知数据的标注非常昂贵,且自动驾驶中采集的大多数数据都是无标签的。于是我们面临的问题就变成了:如何利用小量有标签数据和大量无标签数据来训练感知模型?在机器学习中,这是标准的半监督学习问题,有两套解决思路:
a、无监督预训练+微调。即利用对比学习(如SimCLR, SimSiam),掩码预测(如BeiT,MAE)等方法预训练,然后利用参数作为初始化,在下游感知任务上进行微调。
b、自训练,这是百度选择的方法,可以同时使用有标签和无标签的数据来学习。具体来说,先使用有标签数据对模型进行初始启动训练,然后将模型在无标签数据上进行推理得到伪标签,最后合并有标签数据和伪标签数据对模型进行进一步训练。如此往复,进行多轮迭代。
在训练完感知大模型以后,百度利用知识蒸馏的方法将伪标签用于车载小模型的学习,从而增强车载小模型的远距离感知能力。
百度选择自训练的原因,我相信是在实际使用中,这种自训练的范式能得到更好的下游任务表现。在一些论文里,我们也能找到这方面的证据,感兴趣的同学可以阅读论文Rethinking pre-training and self-training[3]获取更多细节。
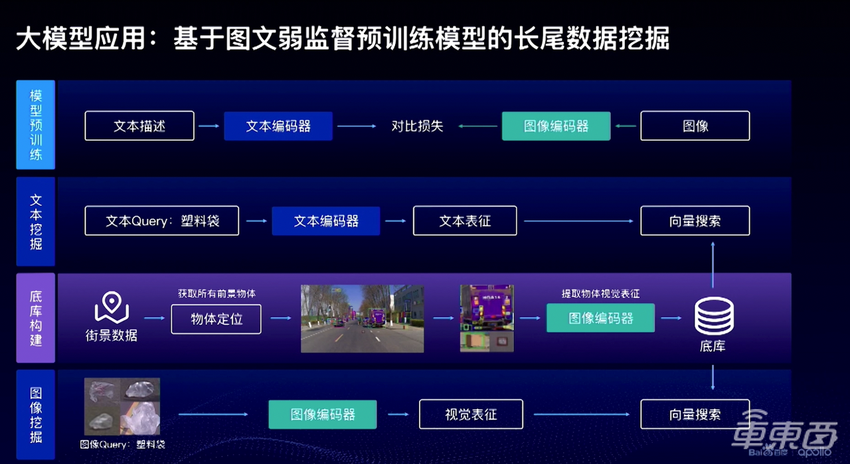
▲图文大模型用于长尾数据挖掘
2、“文心大模型-图文弱监督预训练模型”。
前一个感知大模型的用处主要是提高3D感知能力,而这个图文大模型主要用来在云端做长尾数据挖掘,关注语义层面的理解能力。图文弱监督大模型包含一个文本编码器和一个图像编码器,在海量的(2D图片,文字)对上通过对比学习得到,这个方向最经典的研究工作就是CLIP[4]。在训练完图文大模型以后,长尾物体挖掘的流程如下:
a、对于一个庞大的自动驾驶数据集,使用一个高召回率的物体检测器,检测所有可能是物体的框,这里使用的是Group DETR v2[5];
b、利用图文弱监督大模型训练出来的图像编码器,对每个物体编码,得到物体的特征向量;
c、在挖掘时,可以使用(i)文本进行图像挖掘;(ii)图像进行相似图像的挖掘。下图中展示了许多大模型可以挖掘出的有意思的物体类别,如塑料袋,消防车/救护车,轮椅,动物等等。
D、可以选择性地对挖掘出来的图文对进行筛选,放入训练集进行大模型的进一步提升。

▲数据挖掘效果示例
大模型在AI领域最近有很多研究成果,不少自动驾驶公司也声称在探索。百度Apollo应该是首个公开详细展示技术原理和亮点的自动驾驶团队,这在行业里算是一次重要的尝试。而百度应用大模型的两种思路,显然也会给其他团队提供指引和参考,预计今后在自动驾驶行业中会涌现出更多大模型的研发和应用。
二、高精地图再进化 引入人类驾驶经验
高精度地图是自动驾驶领域的另一个热门话题。百度是同时具有自动驾驶业务和绘图资质的公司,因此是高精度地图的支持者和开发者。在黄际洲讲解的L4地图和王亮讲解的L2+地图中都有提到,百度对于传统高精度地图建图存在的一些核心挑战,提出了一系列的解决方案:
1、高精度地图构建成本高昂怎么解决?用AI技术低成本、高效率自动化生产高精度地图,自动化率达到96%。
2、道路结构发生变化怎么解决?融合车端的实时感知地图和高精地图,输出最终融合后的地图结果,解决地图和现实不一致的问题。
对于当下比较火的无高精度地图(实时地图感知)方案,百度给出了以下对比,并且表示这种低成本、融合的地图方案,可以更好地保证自动驾驶的安全性。

▲无高精度地图方案和Apollo自研的“轻量”高精地图对比
我们注意到另一个有独特的概念是百度提出的驾驶知识图谱。
驾驶知识图谱包含了一些人类驾驶的一些经验性知识,例如出匝道时不应该立刻减速,而应该缓慢减速保证舒适和安全。驾驶知识图谱的构建基于百度地图收集的数亿人类司机驾驶习惯,包括经验速度、变道时机等,从而帮助无人车做到更好的规划控制。
从技术角度来看,有高精地图的加持,会让自动驾驶汽车拥有更好的驾驶表现。同时有自动驾驶和高精地图业务的百度这次在技术上的突破值得关注。
三、PNC融入深度学习 预测决策联合建模
基于学习的规控系统(PNC)是业界大家普遍关注的问题,很多人会开玩笑说,业界的规控代码就是一些if-else的堆砌。其实这样的比喻并不夸张。PNC一般包括了预测、决策、轨迹规划和控制四个部分,预测、决策和轨迹规划都是非常困难的问题。
经典的预测方法是基于地图规则和动力学模型的。过去几年,轨迹预测模块逐渐引入了一系列深度学习的方案如TNT、SceneTransformer,都使得预测能力显著提升。
经典的决策方案会根据场景进行拆分,例如高速、路口、环岛,然后根据每一种场景下的车辆状态进行规则拆分,例如匀速、减速、变道、加塞。这样我们就有了一个复杂的有限状态机,状态机的节点是行为决策,边是状态变化的条件。
如何拆分是每个公司自己积累的“手艺”,如果拆分的好,整个图的结构会比较清晰,如果拆分的不好,往往随着系统更新、策略分叉,变成一个规则补丁系统。更困难的是,随着驾驶城市的扩展,不同城市的同样场景可能有差异,需要不同决策,最终导致决策分叉爆炸,难以维护。
经典的轨迹规划方案通常先根据可行区域进行路径搜索,然后对得到的粗略轨迹进行优化,求解出一条安全和可行的时空轨迹。
百度的学习型PNC方案是将预测和决策两个模块联合建模,然后送入到轨迹规划和控制模块中。具体来说:
1、先提取场景里自车特征,环境车辆的特征,地图的特征,使用一个Scene Transformer来融合特征;
2、输出两个分支,一个分支输出环境车的决策和轨迹;
3、另一个分支输出自车规划的轨迹初始值(trajectory seeds);
4、将轨迹初始值输入到轨迹规划模块,进行进一步的搜索和优化,得到最终的轨迹。
以上的方案是一个比较端到端的方法,搭建端到端的模型并不是最困难的,更难的问题是,在没有规则约束下(如“红灯停绿灯行”),如何保证模型的输出决策的合理性呢?百度给出的答案是,利用经验系统来初始化决策模型,让模型的表现接近规则系统,然后让模型利用真实数据进行迭代,逐渐超越经验系统。此外,由于轨迹规划模块的存在,仍然可以兜底确保最后轨迹的安全性。
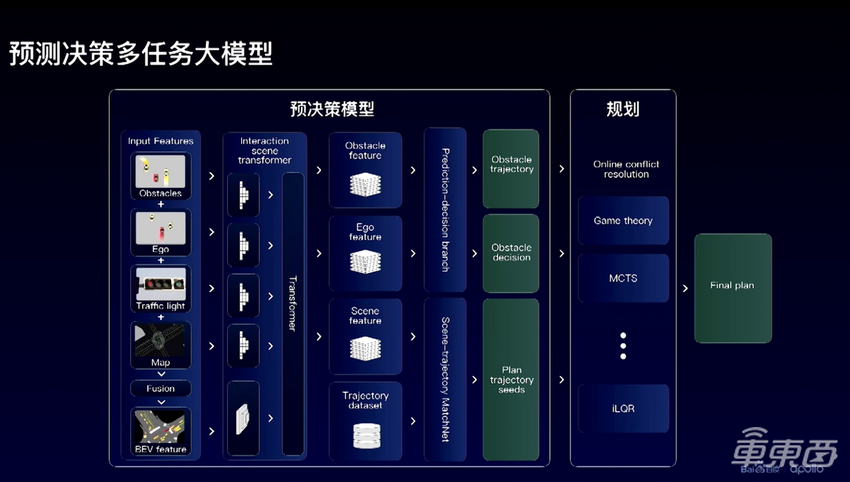
▲预测决策大模型结构
学习型的PNC模块是自动驾驶学术和产业的技术前沿。学术界虽然提出了不少研究成果,但在产业界其实应用的案例并不丰富,甚至可以说只是在尝试阶段。百度此次提出的预测决策一体化模型,在底层设计上实现的创新,是行业在实现PNC范式变革上迈出的重要一步。
四、数据质量比规模重要 创新方式实现数据闭环
我觉得本次技术日的另一大亮点是数据闭环。随着路测数据的增加,自动驾驶模型的学习是一个持续提升的过程,因此构建数据闭环也是自动驾驶的核心能力。
数据闭环的第一个方面便是数据采集。
百度李昂首先提出,数据纯度比数据规模更加重要。数据提纯的重要步骤就是数据挖掘。刚才我们提到了用大模型在云端进行数据挖掘,其实数据挖掘不仅可以在云端做,也要在车端做。无人车每秒钟都会收集到几十MB的数据量,网络无法支撑全量的数据回传,因此在车端就要进行数据的筛选,把那些在模型决策边界(置信度低)的数据回传,实现主动学习。

▲云端数据提纯
数据闭环的另一个方面就是自动化的模型训练。自动化模型训练有两个关键技术,第一是自动化模型搜索(AutoML),第二是持续学习(Continual Learning)。自动化模型搜索指让训练系统自动进行模型调优,AutoML在过去几年是比较红火的研究方向,也有许多论文和实践的探索。百度使用的是一种基于进化算法改进的方案,主要搜索模型的超参数,如任务的权重、optimizer的参数等。感兴趣的同学可以参考论文Population-based training [6]。
而这里提到的持续学习是最近AI研究者们更为关注的课题,深度学习在新的数据持续注入模型训练的过程中,会体现出两个缺陷:(1)灾难性遗忘(catastropic forgetting),即学了新的数据以后在旧的数据上容易发生遗忘;(2)可塑性损失(loss of plasticity),即模型在多次训练以后,在新数据上的学习能力变差/慢。
因此,如何让模型在旧的数据上和新的数据上都表现的好,是一个很有挑战的trade-off。百度所采用的,buffer replay是解决灾难性遗忘的有效方法,continual backprop是解决可塑性损失的有效方案。感兴趣的同学可以阅读相关论文Experience Replay[7]和Continual Backprop[8]。
在打通以上数据挖掘和自动训练的环节之后,模型就可以实现持续的提升和迭代了。下图中展示的是随着自动化训练,模型在普通物体和小物体上的表现都得到了提升。

▲数据挖掘和自动训练引擎
在数据闭环的演讲最后,有一个技术点让我觉得眼前一亮。
我们知道,自动驾驶的算法流程是一个串行结构,包括感知-预测-规划,但是优化局部模块不代表最终带来自动驾驶能力的提升。以预测为例,更好的轨迹预测并不代表能带来更好的决策规划结果。
而在百度的自动模型搜索的方案中,通过后期的仿真评测,得到一系列(模型,预测指标,仿真指标)的数据对,因此可以训练一个简单的线性回归层,学习预测指标到仿真指标的相关性,这也代表了不同场景下障碍物的预测能力对仿真效果的重要度。通过这样的方式,就可以在搜索预测模型的时候,同时达到仿真的需求,减少掉入局部最优的可能性。
自动驾驶是一个系统性工程,李昂本次关于数据闭环技术的分享,展现了百度在自动驾驶方面进行的是系统的技术创新:既关注常见的感知、决策、控制环节,又在AI算法最关键的数据提纯、标注和模型训练环节进行大胆创新,用新的技术思路和解题模式提升底层技术的支撑力,最终又反过来能促进感知、决策等环节的发展。
五、只有技术创新才能推动无人车落地
当下的自动驾驶,尤其是高等级的自动驾驶系统迟迟无法规模商用的原因,主要是有几大技术问题难以解决导致,包括:感知中的长尾物体难识别、高精地图成本高难以维护、决策规划过分依赖规则、算法能力难以随数据持续提升等等…
这些问题在全球范围内导致无人车落地进度较慢,因而最近几年里外界也时不时会出现了一些看衰无人车和高等级自动驾驶行业的杂音。
回到技术本身,上述这些技术问题真的就无解吗?答案显然是否定的,一方面学术界各种专家在积极进行技术研究,不断提出像是BEV、大模型等新的方法。另一方面拥有国内最庞大技术团队的百度显然也在积极把这些前沿的技术方法投入到实际的产品研发之中。
本次百度Apollo技术日分享的内容就是最佳的例证:大模型用于克服长尾和困难物体的感知;提高建图的自动化程度,降低高精度地图成本;预测决策模块一体化学习方案解决了规则决策的问题;数据闭环打通数据-模型-指标的自动化反馈能力,持续高效提升模型效果…
在这些新技术的加持下,显然将让百度和整个中国的高等级自动驾驶车辆更大规模的落地又近了一步。
[1] Liu, Z., Tang, H., Amini, A., Yang, X., Mao, H., Rus, D. and Han, S., 2022. BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation. arXiv preprint arXiv:2205.13542.
[2] Chen, X., Zhang, T., Wang, Y., Wang, Y. and Zhao, H., 2022. Futr3d: A unified sensor fusion framework for 3d detection. arXiv preprint arXiv:2203.10642.
[3] Zoph, B., Ghiasi, G., Lin, T.Y., Cui, Y., Liu, H., Cubuk, E.D. and Le, Q., 2020. Rethinking pre-training and self-training. Advances in neural information processing systems, 33, pp.3833-3845.
[4] Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J. and Krueger, G., 2021, July. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning (pp. 8748-8763). PMLR.
[5] Chen, Q., Wang, J., Han, C., Zhang, S., Li, Z., Chen, X., Chen, J., Wang, X., Han, S., Zhang, G. and Feng, H., 2022. Group detr v2: Strong object detector with encoder-decoder pretraining. arXiv preprint arXiv:2211.03594.
[6] Jaderberg, M., Dalibard, V., Osindero, S., Czarnecki, W.M., Donahue, J., Razavi, A., Vinyals, O., Green, T., Dunning, I., Simonyan, K. and Fernando, C., 2017. Population based training of neural networks. arXiv preprint arXiv:1711.09846.
[7] Rolnick, D., Ahuja, A., Schwarz, J., Lillicrap, T. and Wayne, G., 2019. Experience replay for continual learning. Advances in Neural Information Processing Systems, 32.
[8] Dohare, S., Mahmood, A.R. and Sutton, R.S., 2021. Continual backprop: Stochastic gradient descent with persistent randomness. arXiv preprint arXiv:2108.06325.

