







 21
21
智东西7月1日消息,阿里通义实验室开源了旗下首个音频生成模型ThinkSound。该模型首次将CoT(思维链)应用到音频生成领域,让AI可以像专业音效师一样逐步思考,捕捉视觉细节,生成与画面同步的高保真音频。ThinkSound的代码和模型已在Github、HuggingFace、魔搭社区开源,开发者可免费下载和体验。
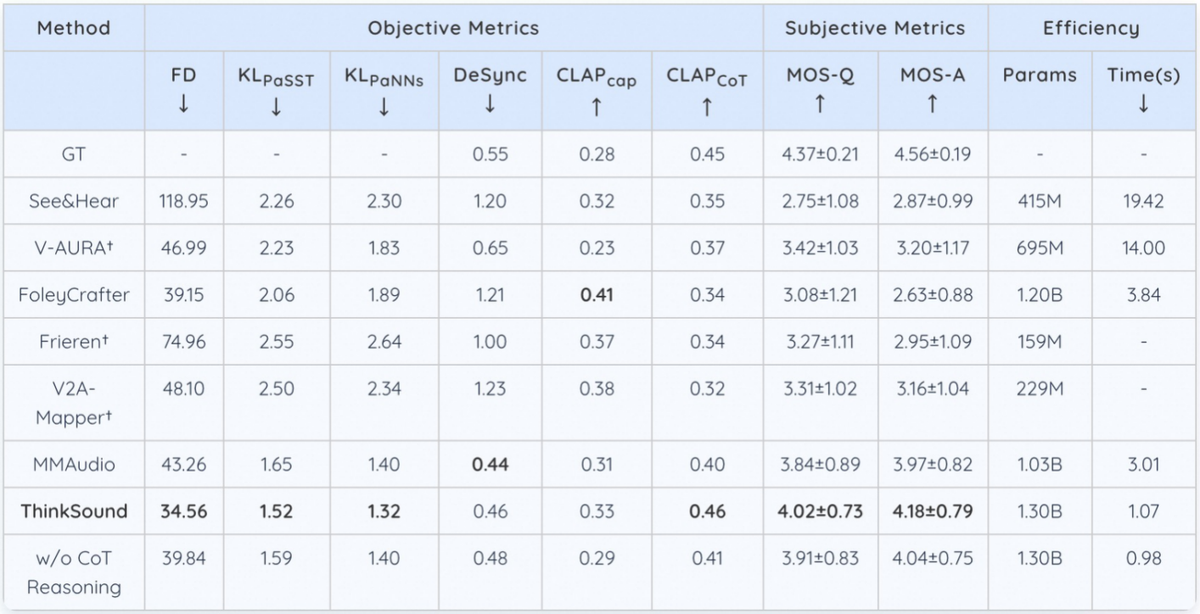
在开源的VGGSound测试集上,ThinkSound的核心指标相比MMAudio、V2A-Mappe、V-AURA等现有主流方法均实现了15%以上的提升。例如,在openl3空间中Fréchet 距离(FD)上,ThinkSound 相比 MMAudio的43.26 降至34.56(越低越好),接近真实音频分布的相似度提高了20%以上;在代表模型对声音事件类别和特征判别精准度的KLPaSST 和 KLPaNNs两项指标上分别取得了1.52和1.32的成绩,均为同类模型最佳。
目前,通义实验室已推出语音生成大模型Cosyvoice、端到端音频多模态大模型MinMo等模型,全面覆盖语音合成、音频生成、音频理解等场景。
开源地址:
https://github.com/liuhuadai/ThinkSound
https://huggingface.co/liuhuadai/ThinkSound
https://www.modelscope.cn/studios/AudioGeneral/ThinkSound




