







 37
37
智东西11月8日消息,今日,中文大模型测评基准SuperCLUE发布《中文大模型基准测评2024年10月报告》,其中商汤日日新·商量大模型(SenseChat5.5)总得分位列国内大模型第一梯队,获得金牌。SuperCLUE报告显示,国内大模型的能力与ChatGPT-4o-latest表现接近,o1-preview则在复杂任务中更为突出。
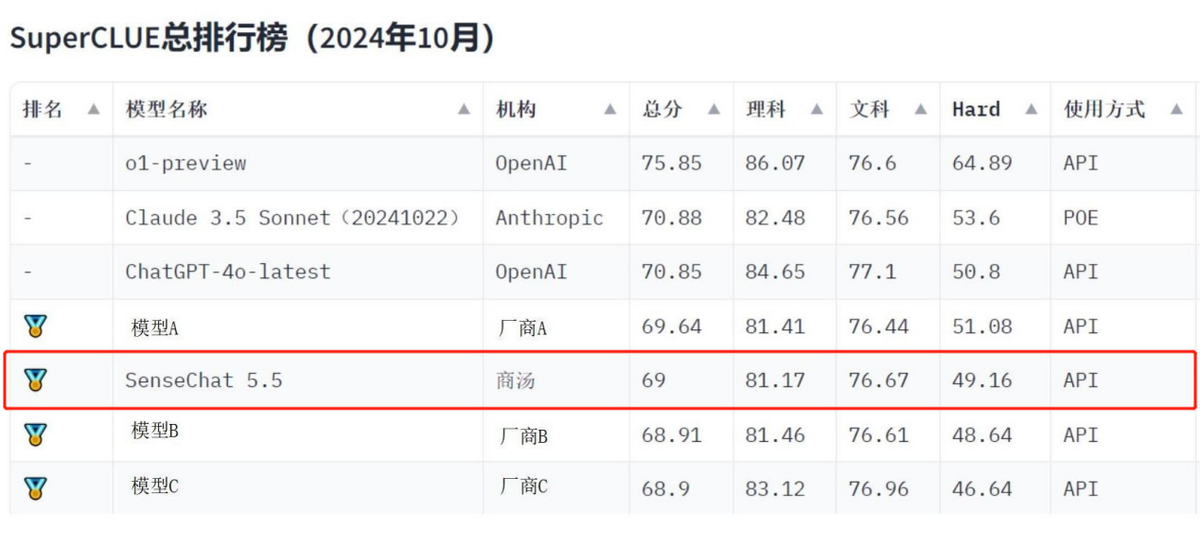
本次SuperCLUE10月报告覆盖23个国内模型,聚焦语言大模型的通用能力评估,分为三大维度:除了考察“文科”、“理科”基础能力外,还有考察模型更高阶能力的“Hard”附加任务,总共2900+道题。商汤SenseChat5.5在多项评测任务中均位列第一梯队,文科中语言理解、安全等维度表现突出,理科中逻辑推理、代码等维度表现突出。在【Hard】的两项任务——精准指令遵循和高阶推理中,商汤SenseChat5.5是唯一两项任务均位于国内第一梯队的大模型。




